

The genetic code is nearly optimal for allowing additional information within protein-coding sequences 1
DNA sequences that code for proteins need to convey, in addition to the protein-coding information, several different signals at the same time. These “parallel codes” include binding sequences for regulatory and structural proteins, signals for splicing, and RNA secondary structure. Here, we show that the universal genetic code can efficiently carry arbitrary parallel codes much better than the vast majority of other possible genetic codes. This property is related to the identity of the stop codons. We find that the ability to support parallel codes is strongly tied to another useful property of the genetic code—minimization of the effects of frame-shift translation errors. Whereas many of the known regulatory codes reside in nontranslated regions of the genome, the present findings suggest that protein-coding regions can readily carry abundant additional information.
Evolution Professor: DNA Code Indicates Common Descent Because ... Why? 2
But if the code cannot be changed, then how did it evolve in the first place? The very universality which Coyne celebrates undercuts the theory Coyne is so sure is a fact.
Imagine the gradual evolutionary steps leading to the DNA code. In the penultimate step, the code was slightly different. And in the step before that, it was a slightly more different code. And so forth. The code must have been evolving—it must have been changing. And yet suddenly the code could no longer evolve. It makes no sense and, beyond hand-waving, proponents of evolution have no explanation for it.
Furthermore the code is also unique and special. It has several profound properties that are very helpful. For instance its arrangement is such that the effects of copying errors are minimized. Not only did the code just happen to evolve in early evolution, evolution just happened to find a one-in-a-million code.
The genetic code is one in a million 3
if we employ weightings to allow for biases in translation, then only 1 in every million random alternative codes generated is more efficient than the natural code. We thus conclude not only that the natural genetic code is extremely efficient at minimizing the effects of errors, but also that its structure reflects biases in these errors, as might be expected were the code the product of selection.
Fazale Rana writes in his book Cell's design, pg.176 :
Recently, scientists have worked to quantitatively evaluate the error-minimization capacity of the genetic code. One of the first studies to perform this analysis indicated that the universal genetic code found in nature could withstand the potentially harmful effects of substitution mutations better than all but 0.02 percent (1 out of 5,000) of randomly generated genetic codes with different codon assignments than the one found throughout nature. This initial work, however, did not take into account the fact that some types of substitution mutations occur more frequently in nature than others. For example, an A-to-G substitution occurs more often than either an A- to-C or an A-to-T mutation. When researchers incorporated this correction into their analysis, they discovered that the naturally occurring genetic code performed better than one million randomly generated genetic codes and that the genetic code in nature resides near the global optimum for all possible genetic codes with respect to its error-minimization capacity. Nature's universal genetic code is truly one in a million! The genetic code's error-minimization properties are far more dramatic than these results indicate. When the researchers calculated the error-mini- mization capacity of the one million randomly generated genetic codes, they discovered that the error-minimization values formed a distribution with the naturally occurring genetic code lying outside the distribution.
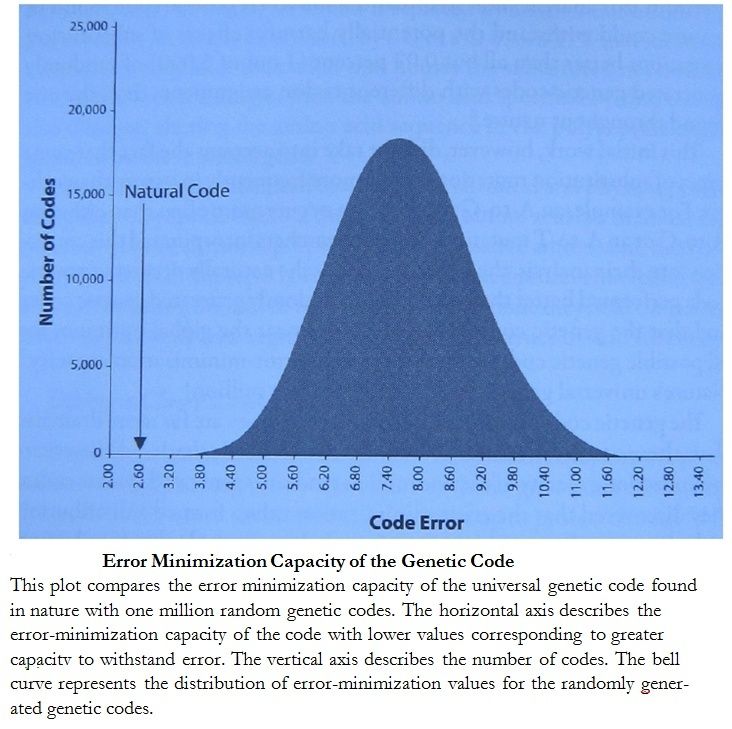
Researchers estimate the existence of 10^18 possible genetic codes possessing the same type and degree of redundancy as the universal genetic code. All of these codes fall within the error-minimization distribution. This means of 10^18 possible genetic codes few, if any, have an error-minimization capacity that approaches the code found universally throughout nature. Some researchers have challenged the optimality of the genetic code. But, the scientists who discovered the remarkable error-minimization capacity of the genetic code have concluded that the rules of the genetic code cannot be accidental. A genetic code assembled through random biochemical events could not possess near ideal error-minimization properties. Researchers argue that a force shaped the genetic code. Instead of looking to an intentional Programmer, these scientists appeal to natural selection. That is, they believe random events operated on by the forces of natural selection over and over again produced the genetic code's error-minimization capacity.
Even though some researchers think natural selection shaped the genetic code, other scientific work questions the likelihood that the genetic code could evolve. In 1968, Nobel laureate Francis Crick argued that the genetic code could not undergo significant evolution. His rationale is easy to understand. Any change in codon assignments would lead to changes in amino acids in every polypeptide made by the cell. This wholesale change in polypeptide sequences would result in a large number of defective proteins. Nearly any conceivable change to the genetic code would be lethal to the cell. The scientists who suggest that natural selection shaped the genetic code are fully aware of Crick's work. Still they rely on evolution to explain the code's optimal design because of the existence of nonuniversal genetic codes.
While the genetic code in nature is generally regarded as universal, some non- universal genetic codes exist—codes that employ slightly different codon assignments. Presumably, these nonuniversal codes evolved from the universal genetic code. Therefore, researchers argue that such evolution is possible. But, the codon assignments of the nonuniversal genetic codes are nearly identical to those of the universal genetic code with only one or two exceptions. Nonuniversal genetic codes can be thought of as deviants of the uni- versal genetic code. Does the existence of nonuniversal codes imply that wholesale genetic code evolution is possible ? Careful study reveals that codon changes in the nonuniversal genetic codes always occur in relatively small genomes, such as those in mitochondria. These changes involve (1) codons that occur at low frequencies in that particular genome or (2) stop codons. Changes in assignment for these codons could occur without producing a lethal scenario because only a small number of polypeptides in the cell or or- ganelle would experience an altered amino acid sequence. So it seems limited evolution of the genetic code can take place, but only in special circumstances. The existence of nonuniversal genetic codes does not necessarily justify an evolutionary origin of the amazingly optimal genetic code found in nature.
Is a Timely Rescue Possible?
Even if the genetic code could change over time to yield a set of rules that allowed for the best possible error-minimization capacity, is there enough time for this process to occur? Biophysicist Hubert Yockey addressed this question. He determined that natural selection would have to explore 1.40 x 10^70 different genetic codes to discover the universal genetic code found in nature. The maximum time available for it to originate was estimated at 6.3 x 10^15 seconds. Natural selection would have to evaluate roughly 10^55 codes per second to find the one that's universal. Put simply, natural selection lacks the time necessary to find the universal genetic code. Other work places the genetic code's origin coincidental with life's start. Operating within the evolutionary paradigm, a team headed by renowned origin-of-life researcher Manfred Eigen estimated the age of the genetic code at 3.8 ± 0.6 billion years. Current geochemical evidence places life's first appearance on Earth at 3.86 billion years ago. This timing means that the genetic code's origin coincides with life's start on Earth. It appears as if the genetic code came out of nowhere, without any time to search out the best option.
In the face of these types of problems, some scientists suggest that the genetic code found in nature emerged from a simpler code that employed codons consisting of one or two nucleotides. Over time, these simpler genetic codes expanded to eventually yield the universal genetic code based on coding triplets. The number of possible genetic codes based on one or two nucleotide codons is far fewer than for codes based on coding triplets. This scenario makes code evolution much more likely from a naturalistic standpoint. One complicating factor for these proposals arises, however, from the fact that simpler genetic codes cannot specify twenty different amino acids. Rather, they are limited to sixteen at most. Such a scenario would mean that the first lifeforms had to make use of proteins that consisted of no more than sixteen different amino acids. Interestingly, some proteins found in nature, such as ferredoxins, are produced with only thirteen amino acids. On the surface, this observation seems to square with the idea that the genetic code found in nature arose from a simpler code. Yet, proteins like the ferredoxins are atypical. Most proteins require all twenty amino acids. This requirement, coupled with recent recognition that life in its most minimal form needs several hundred proteins , makes these types of models for code evolution speculative at best. The optimal nature of the genetic code and the difficulty accounting for the code's origin from an evolutionary perspective work together to support the conclusion that an Intelligent Designer programmed the genetic code, and hence, life.
1) http://genome.cshlp.org/content/17/4/405.abstract
2) http://darwins-god.blogspot.com.br/2014/09/evolution-professor-dna-code-indicates.html
3) http://www.ncbi.nlm.nih.gov/pubmed/9732450
DNA sequences that code for proteins need to convey, in addition to the protein-coding information, several different signals at the same time. These “parallel codes” include binding sequences for regulatory and structural proteins, signals for splicing, and RNA secondary structure. Here, we show that the universal genetic code can efficiently carry arbitrary parallel codes much better than the vast majority of other possible genetic codes. This property is related to the identity of the stop codons. We find that the ability to support parallel codes is strongly tied to another useful property of the genetic code—minimization of the effects of frame-shift translation errors. Whereas many of the known regulatory codes reside in nontranslated regions of the genome, the present findings suggest that protein-coding regions can readily carry abundant additional information.
Evolution Professor: DNA Code Indicates Common Descent Because ... Why? 2
But if the code cannot be changed, then how did it evolve in the first place? The very universality which Coyne celebrates undercuts the theory Coyne is so sure is a fact.
Imagine the gradual evolutionary steps leading to the DNA code. In the penultimate step, the code was slightly different. And in the step before that, it was a slightly more different code. And so forth. The code must have been evolving—it must have been changing. And yet suddenly the code could no longer evolve. It makes no sense and, beyond hand-waving, proponents of evolution have no explanation for it.
Furthermore the code is also unique and special. It has several profound properties that are very helpful. For instance its arrangement is such that the effects of copying errors are minimized. Not only did the code just happen to evolve in early evolution, evolution just happened to find a one-in-a-million code.
The genetic code is one in a million 3
if we employ weightings to allow for biases in translation, then only 1 in every million random alternative codes generated is more efficient than the natural code. We thus conclude not only that the natural genetic code is extremely efficient at minimizing the effects of errors, but also that its structure reflects biases in these errors, as might be expected were the code the product of selection.
Fazale Rana writes in his book Cell's design, pg.176 :
Recently, scientists have worked to quantitatively evaluate the error-minimization capacity of the genetic code. One of the first studies to perform this analysis indicated that the universal genetic code found in nature could withstand the potentially harmful effects of substitution mutations better than all but 0.02 percent (1 out of 5,000) of randomly generated genetic codes with different codon assignments than the one found throughout nature. This initial work, however, did not take into account the fact that some types of substitution mutations occur more frequently in nature than others. For example, an A-to-G substitution occurs more often than either an A- to-C or an A-to-T mutation. When researchers incorporated this correction into their analysis, they discovered that the naturally occurring genetic code performed better than one million randomly generated genetic codes and that the genetic code in nature resides near the global optimum for all possible genetic codes with respect to its error-minimization capacity. Nature's universal genetic code is truly one in a million! The genetic code's error-minimization properties are far more dramatic than these results indicate. When the researchers calculated the error-mini- mization capacity of the one million randomly generated genetic codes, they discovered that the error-minimization values formed a distribution with the naturally occurring genetic code lying outside the distribution.
Researchers estimate the existence of 10^18 possible genetic codes possessing the same type and degree of redundancy as the universal genetic code. All of these codes fall within the error-minimization distribution. This means of 10^18 possible genetic codes few, if any, have an error-minimization capacity that approaches the code found universally throughout nature. Some researchers have challenged the optimality of the genetic code. But, the scientists who discovered the remarkable error-minimization capacity of the genetic code have concluded that the rules of the genetic code cannot be accidental. A genetic code assembled through random biochemical events could not possess near ideal error-minimization properties. Researchers argue that a force shaped the genetic code. Instead of looking to an intentional Programmer, these scientists appeal to natural selection. That is, they believe random events operated on by the forces of natural selection over and over again produced the genetic code's error-minimization capacity.
Even though some researchers think natural selection shaped the genetic code, other scientific work questions the likelihood that the genetic code could evolve. In 1968, Nobel laureate Francis Crick argued that the genetic code could not undergo significant evolution. His rationale is easy to understand. Any change in codon assignments would lead to changes in amino acids in every polypeptide made by the cell. This wholesale change in polypeptide sequences would result in a large number of defective proteins. Nearly any conceivable change to the genetic code would be lethal to the cell. The scientists who suggest that natural selection shaped the genetic code are fully aware of Crick's work. Still they rely on evolution to explain the code's optimal design because of the existence of nonuniversal genetic codes.
While the genetic code in nature is generally regarded as universal, some non- universal genetic codes exist—codes that employ slightly different codon assignments. Presumably, these nonuniversal codes evolved from the universal genetic code. Therefore, researchers argue that such evolution is possible. But, the codon assignments of the nonuniversal genetic codes are nearly identical to those of the universal genetic code with only one or two exceptions. Nonuniversal genetic codes can be thought of as deviants of the uni- versal genetic code. Does the existence of nonuniversal codes imply that wholesale genetic code evolution is possible ? Careful study reveals that codon changes in the nonuniversal genetic codes always occur in relatively small genomes, such as those in mitochondria. These changes involve (1) codons that occur at low frequencies in that particular genome or (2) stop codons. Changes in assignment for these codons could occur without producing a lethal scenario because only a small number of polypeptides in the cell or or- ganelle would experience an altered amino acid sequence. So it seems limited evolution of the genetic code can take place, but only in special circumstances. The existence of nonuniversal genetic codes does not necessarily justify an evolutionary origin of the amazingly optimal genetic code found in nature.
Is a Timely Rescue Possible?
Even if the genetic code could change over time to yield a set of rules that allowed for the best possible error-minimization capacity, is there enough time for this process to occur? Biophysicist Hubert Yockey addressed this question. He determined that natural selection would have to explore 1.40 x 10^70 different genetic codes to discover the universal genetic code found in nature. The maximum time available for it to originate was estimated at 6.3 x 10^15 seconds. Natural selection would have to evaluate roughly 10^55 codes per second to find the one that's universal. Put simply, natural selection lacks the time necessary to find the universal genetic code. Other work places the genetic code's origin coincidental with life's start. Operating within the evolutionary paradigm, a team headed by renowned origin-of-life researcher Manfred Eigen estimated the age of the genetic code at 3.8 ± 0.6 billion years. Current geochemical evidence places life's first appearance on Earth at 3.86 billion years ago. This timing means that the genetic code's origin coincides with life's start on Earth. It appears as if the genetic code came out of nowhere, without any time to search out the best option.
In the face of these types of problems, some scientists suggest that the genetic code found in nature emerged from a simpler code that employed codons consisting of one or two nucleotides. Over time, these simpler genetic codes expanded to eventually yield the universal genetic code based on coding triplets. The number of possible genetic codes based on one or two nucleotide codons is far fewer than for codes based on coding triplets. This scenario makes code evolution much more likely from a naturalistic standpoint. One complicating factor for these proposals arises, however, from the fact that simpler genetic codes cannot specify twenty different amino acids. Rather, they are limited to sixteen at most. Such a scenario would mean that the first lifeforms had to make use of proteins that consisted of no more than sixteen different amino acids. Interestingly, some proteins found in nature, such as ferredoxins, are produced with only thirteen amino acids. On the surface, this observation seems to square with the idea that the genetic code found in nature arose from a simpler code. Yet, proteins like the ferredoxins are atypical. Most proteins require all twenty amino acids. This requirement, coupled with recent recognition that life in its most minimal form needs several hundred proteins , makes these types of models for code evolution speculative at best. The optimal nature of the genetic code and the difficulty accounting for the code's origin from an evolutionary perspective work together to support the conclusion that an Intelligent Designer programmed the genetic code, and hence, life.
1) http://genome.cshlp.org/content/17/4/405.abstract
2) http://darwins-god.blogspot.com.br/2014/09/evolution-professor-dna-code-indicates.html
3) http://www.ncbi.nlm.nih.gov/pubmed/9732450