

The language of the genetic code
https://reasonandscience.catsboard.com/t1472-the-language-of-the-genetic-code
The word language is from Vulgar Latin *linguaticum, from Latin lingua "tongue," also "speech, language," from PIE root *dnghu- "tongue." Speaking is translated, parlare in Italian, or From Vulgar Latin parolāre, back formation of Late Latin paravola, from Latin parabola (“comparison”), from Ancient Greek παραβολή (parabolḗ). παραβολή • (parabolḗ) f (genitive παραβολῆς); first declension a placing of two things side by side, juxtaposition. Computers nor cells do have intelligent capabilities, but in order for a computer able to host an instructional code, that can be translated, intelligent implementation is necessary. AND, this may be the key point, there are two things put side a side. On the one side, the genetic informational instruction, and on the other, the translated result, the sequence of amino acids, that are sequenced based on that instruction, using the translation mechanism, based on the genetic code. So, it is that genetic code, that makes the " putting side a side" possible. It is the essential "key". Therefore, the genetic code is indeed a language. I might not understand the meaning of codons ( as the code was only cracked in the 1960s by Nirenberg) or maybe the code or language itself has no knowledge of itself. But that is not necessary for it to function as a language, or a key, that is able to put two things side aside. So, i, as an intelligent being, am able to use language and understand what I am saying. But if there is a program, a computer code, a cipher, that is preprogrammed to exercise the transmission of information, even if not by itself conscious, it exercises a function based on implemented language, the elements that make that translation possible, are indeed a language.
Marshall Nirenburg, an American at the National Institutes of Health in Maryland, performed experiments that enabled scientists to decipher the genetic code.
MARSHALL W. NIRENBERG Will Society Be Prepared? 11 August 1967,
The genetic language now is known. and it seems clear that most, if not all, forms of life on this planet use the same language. with minor variations.
https://science.sciencemag.org/content/sci/157/3789/633.full.pdf
Complex grammar of the genomic language November 10, 2015
A new study from Sweden’s Karolinska Institutet shows that the ‘grammar’ of the human genetic code is more complex than that of even the most intricately constructed spoken languages in the world. The findings, published in the journal Nature, explain why the human genome is so difficult to decipher – and contribute to the further understanding of how genetic differences affect the risk of developing diseases on an individual level. “The genome contains all the information needed to build and maintain an organism, but it also holds the details of an individual’s risk of developing common diseases such as diabetes, heart disease and cancer”, says study lead-author Arttu Jolma, doctoral student at the Department of Biosciences and Nutrition. “If we can improve our ability to read and understand the human genome, we will also be able to make better use of the rapidly accumulating genomic information on a large number of diseases for medical benefits.”
https://health.economictimes.indiatimes.com/news/industry/complex-grammar-of-the-genomic-language/49731356
Cell Biology December 29, 2013
In the alphabet of the three letter word found in cell biology are the organic bases, which are adenine (A), guanine (G), cytosine (C) and thymine (T). It is the triplet recipe of these
bases that make up the ‘dictionary’ we call in molecular biology genetic code. The codal system enables the transmission of genetic information to be codified, which at molecular level, is conveyed through genes.
https://upload.wikimedia.org/wikipedia/commons/1/17/Cell_Biology.pdf
Bert hubert DNA seen through the eyes of a coder (or, If you are a hammer, everything looks like a nail) Jan 09 2021
The language of DNA is digital, but not binary. Where binary encoding has 0 and 1 to work with (2 - hence the 'bi'nary), DNA has 4 positions, T, C, G and A. Whereas a digital byte is mostly 8 binary digits, a DNA 'byte' (called a 'codon') has three digits. Because each digit can have 4 values instead of 2, an DNA codon has 64 possible values, compared to a binary byte which has 256.
http://ds9a.nl/amazing-dna/
Stephanie Seiler Scientists discover double meaning in genetic code December 12, 2013
Since the genetic code was deciphered in the 1960s, scientists have assumed that it was used exclusively to write information about proteins. UW scientists were stunned to discover that genomes use the genetic code to write two separate languages. One describes how proteins are made, and the other instructs the cell on how genes are controlled. One language is written on top of the other, which is why the second language remained hidden for so long.
http://www.washington.edu/news/2013/12/12/scientists-discover-double-meaning-in-genetic-code/
Sungchul Ji’s: The linguistics of DNA Mai 18, 1999
“Biologic systems and processes cannot be fully accounted for in terms of the principles and laws of physics and chemistry alone, but they require in addition the principles of semiotics—the science of symbols and signs, including linguistics.”
Ji identifies 13 characteristics of human language. DNA shares 10 of them. Cells edit DNA. Theyalso communicate with each other and literally speak a language he called “cellese,” described as “a self-organizing system of molecules, some of which encode, act as signs for, or trigger, gene-directed cell processes.” This comparison between cell language and human language is not a loosey-goosey analogy; it’s formal and literal. Human language and cell language both employ multilayered symbols. Dr. Ji explains this similarity in his paper: “Bacterial chemical conversations also include assignment of contextual meaning to words and sentences (semantic) and conduction of dialogue (pragmatic)—the fundamental aspects of linguistic communication.” This is true of genetic material. Signals between cells do this as well.*
“The Linguistics of DNA: Words, Sentences, Grammar, Phonetics, and Semantics”
https://www.academia.edu/33579512/The_Linguistics_of_DNA_Words_Sentences_Grammar_Phonetics_and_Semantics
Vladimir I.shCherbak The “Wow! signal” of the terrestrial genetic code May 2013
In case that there was any doubt about the intelligent origin of DNA, here it is from " Science Direct ";
"Here we show that the terrestrial code displays a thorough precision-type orderliness matching the criteria to be considered an informational signal. Simple arrangements of the code reveal an ensemble of arithmetical and ideographical patterns of the same symbolic language. Accurate and systematic, these underlying patterns appear as a product of precision logic and nontrivial computing rather than of stochastic processes (the null hypothesis that they are due to chance coupled with presumable evolutionary pathways is rejected with P-value < 10–13). The patterns are profound to the extent that the code mapping itself is uniquely deduced from their algebraic representation. The signal displays readily recognizable hallmarks of artificiality, among which are the symbol of zero, the privileged decimal syntax and semantical symmetries. Besides, extraction of the signal involves logically straightforward but abstract operations, making the patterns essentially irreducible to any natural origin.
http://www.sciencedirect.com/science/article/pii/S0019103513000791
Stephen C. Meyer, Signature in the cell :
Crick later developed this idea in his famous “sequence hypothesis,” according to which the chemical parts of DNA (the nucleotide bases) function like letters in a written language or symbols in a computer code. Just as letters in an English sentence or digital characters in a computer program may convey information depending on their arrangement, so too do certain sequences of chemical bases along the spine of the DNA molecule convey precise instructions for building proteins. Like the precisely arranged zeros and ones in a computer program, the chemical bases in DNA convey information in virtue of their “specificity.” As Richard Dawkins notes, “The machine code of the genes is uncannily computer-like.”3 Software developer Bill Gates goes further: “DNA is like a computer program but far, far more advanced than any software ever created.” What the other scientists did dispute was a controversial new hypothesis that Thaxton and his colleagues had floated in the epilogue of their book in an attempt to explain the DNA enigma. They had suggested that the information in DNA might have originated from an intelligent source or, as they put it, an “intelligent cause.” Since, in our experience, information arises from an intelligent source, and since the information in DNA was, in their words, “mathematically identical” to the information in a written language or computer code, they suggested that the presence of information in DNA pointed to an intelligent cause. The code, in other words, pointed to a programmer. A system or sequence of characters manifests “sequence specificity” if the function of the system as a whole depends upon the specific arrangement of the parts. Language has this property. Software has this property. And so too do proteins. Human artifacts and technology—paintings, signs, written text, spoken language, ancient hieroglyphics, integrated circuits, machine codes, computer hardware and software—exhibit specified complexity; among those, software and its encoded sequences of digital characters function in a way that most closely parallels the base sequences in DNA. Thus, oddly, at nearly the same time that computer scientists were beginning to develop machine languages, molecular biologists were discovering that living cells had been using something akin to machine code34 or software35 all along. To quote the information scientist Hubert Yockey again, “The genetic code is constructed to confront and solve the problems of communication and recording by the same principles found…in modern communication and computer codes.”36 Like software, the coding regions of DNA direct operations within a complex material system via highly variable and improbable, yet also precisely specified, sequences of chemical characters. How did these digitally encoded and specifically sequenced instructions in DNA arise? And how did they arise within a channel for transmitting information? As Yockey noted, what needs explaining in biological systems is not order (in the sense of a symmetrical or repeating pattern), but information, the kind of specified digital information found in software, written languages, and DNA. The argument does not depend upon the similarity of DNA to a computer program or human language, but upon the presence of an identical feature in both DNA and intelligently designed codes, languages, and artifacts. Because we know intelligent agents can (and do) produce complex and functionally specified sequences of symbols and arrangements of matter, intelligent agency qualifies as an adequate causal explanation for the origin of this effect. Since, in addition, materialistic theories have proven universally inadequate for explaining the origin of such information, intelligent design now stands as the only entity with the causal power known to produce this feature of living systems.
Sedeer el-Showk The Language of DNA July 28, 2014
One of the striking things about the genetic code is the remarkable way it twists back on itself, combining redundancy and utility in a simple, elegant language. Many of us are introduced to the basic concept in school, but that introduction often leaves out the wrinkles — some of them newly discovered — which give the system its resilience and precision. Despite their complexity, most of these tricks are pretty easy to explain with linguistic analogies, which is precisely what I’m going to try in this post.
Four letters make up the genetic alphabet: A, T, G, and C. In one sense, a gene is nothing more than a sequence of those letters, like TTGAAGCATA…, which has a certain biological meaning or function. But what makes a series of letters have meaning, what gives it a function? In the most straightforward case, it happens because a gene is translated into a protein, a tiny molecular machine. Proteins are made of amino acids, and each gene lists the amino acids that make up a specific protein. Since there are only four genetic letters but 20 different amino acids, the information in a gene is organized into three-letter words called codons; there are only 16 ways of combining four letters into two-letter words, but bumping up the length by a single letter creates 64 possible three-letter words — more than enough to have one for each amino acid. The molecular machinery of the cell assembles a protein by reading through the appropriate gene on a strand of DNA, and stringing together the amino acids that match the codons.
The beauty of the system emerges from the fact that there are 64 possible words but they only need 21 different meanings — 20 amino acids plus a stop sign. That creates the first layer of redundancy, since codons can be synonyms. Just like ‘cup’ and ‘glass’ mean (essentially) the same thing, two different codons can refer to the same amino acid; for example, the GAG and GAA both mean ‘glutamic acid’. Synonymous codons offer some protection against mutation. If the last letter of a GAA happened to mutate into a G in a gene, it would still get a glutamic acid at that point, since GAA and GAG are synonyms.
Of course, synonymous codons don’t completely mask the effect of mutations. Continuing with the example above, if GAA mutated into GAC or GAT, the meaning of the codon would change. Instead of referring to glutamic acid, it would now refer to a different amino acid called aspartic acid. The change in amino acids would affect how the resulting protein functions, which would have consequences for the organism — it might not be able to taste a particular chemical, for example. The change would depend on what the protein normally does and on how different the new amino acid makes it, and that’s where another layer of redundancy comes in. The amino acids can be divided into groups based on important chemical properties, and codons that are similar (but not synonymous) often refer to different amino acids in the same group — that is, to amino acids with similar properties. Even though GAA/GAG and GAC/GAT refer to different amino acids, both are in the ‘polar’ group of amino acids, so the impact is less than if the switch had been to a completely different group. Our languages don’t need the same level of robustness as the genetic code, so there isn’t a similar redundancy (at least, not that I know of). It would be as though English were set up so that any typos of the word ‘cat’ would still be the name of a mammal (like ‘bat’) instead of something completely different (like ‘car’ or ‘hat’).
There’s one more wrinkle, a remarkable trick to get some extra precision out of all this redundancy. In English, synonyms often have slightly different meanings (think of ‘eat’ and ‘dine’, for example), and it turns out that synonyms in the genetic code are also subtly different. A paper published in Science last year showed that the codons at the beginning of a gene affect how strongly that gene is expressed. It’s as though someone described something as ‘a dime for twelve’ instead of ‘a dime a dozen‘; the meaning is exactly the same, but the phrase has less of an impact. Swapping GAA for GAG in a gene doesn’t affect its meaning, but if the change happens near the start of the gene it can change the activity level. (For the more technically inclined: this seems to result from changes in the secondary structure of the mRNA.) It’s an amazing trick, wringing an extra touch of utility out of a system driven by the need for resilience. These processes — the translation of DNA into proteins — are central to the story of evolution, so it’s not surprising to discover that they’ve been exquisitely honed over the aeons. It is beautiful, though.
https://www.nature.com/scitable/blog/accumulating-glitches/the_language_of_dna/
Sandor Schneider, Systems Engineer at Telecommunications
From IT point of view the DNA is a virtual machine with its own machine code. The memory addresses contain 2 bits 00,01,10,11 which are named A,G,T,C (A,G,U,C). Each 3 memory address build a machine code instruction, named “codon”. This is 6 bits. The number of possible instructions 64. The program begins with an “AUG” (methionin) entry point, and there are 3 possible exit point. Just like a computer program. Instructions can create 20 amino acids redundantly
CRI Genetics The Language of DNA 15 NOV, 2019
DNA translation: Everyone speaks a language. Animals speak a language. Computers speak a language. Even your cells speak a language. And like any language, we need to understand the basic rules before we can read and write with it. Four letters make up DNA’s alphabet. These four letters are:
Adenine (A)
Cytosine (C)
Guanine (G)
Thymine (T)
But letters alone do not make a language. I could show you a Cyrillic alphabet, and it wouldn’t mean something to you unless you can speak a Slavic language. In the same way, we need to know what the words are in DNA. Conveniently, all of DNA’s words are the same length. They are all three (3) letters long. Scientists call these three letters a codon. In the following chart, we’ll see what these codons mean.
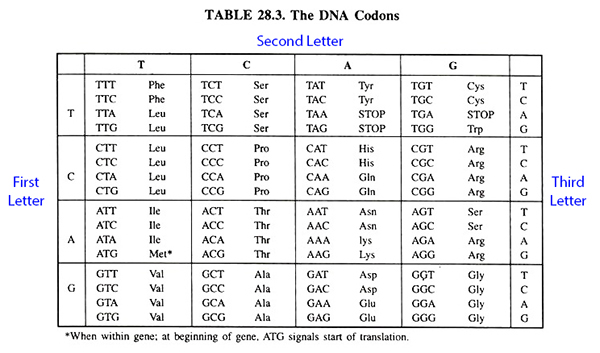
Each codon designates an amino acid. For example, the codon TAT codes for the amino acid Tyrosine. If we continue our analogy, this makes each codon a “word.” These words are the basis of DNA translation. In DNA translation, DNA is converted into a specific sequence of amino acids. But words alone aren’t enough to convey meaning. You need to string words together to form sentences. In the same way, amino acids combine together through DNA translation to form proteins. These sentences need punctuation. Punctuation serves to let you know when a sentence begins, when it ends, and any pauses or gaps in-between. DNA is no different. It uses specific codons to indicate the beginning or ending of a sentence. For example, the codon “ATG” indicates the beginning of an amino acid sequence. For this reason, scientists refer to ATG as the “START” codon. It is always at the beginning of a sentence. Without a START codon, your cells wouldn’t know where to begin making proteins. There are also three codons that act as a “STOP” codon. These three codons (TGA, TAA, TAG) always indicate the end of a sentence. Without a STOP codon, your cells wouldn’t know when to stop making a given protein.
As a demonstration, here’s what an example of a “sentence” might look like in DNA:
ATG TAT CAG GGA TGA
This translates to:
START - Tyrosine - Glutamine - Glycine - STOP
This would produce a protein made of 3 amino acids (Tyr-Glu-Gly). Most proteins are not this short. For example, a hemoglobin subunit is 141 amino acids long.
The Paragraphs
To continue the metaphor of language, sentences aren’t the only part of a written document. Writers clump similar sentences together into paragraphs. And the same is true for proteins. Individual units of protein may come together to form something larger than themselves.
For example, take a hemoglobin molecule:

A hemoglobin molecule consists of eight subunits -- two alpha chains, two beta chains, and four heme groups. These units fold together to hold iron molecules. These iron molecules attract oxygen to hemoglobin. Now I hear you screaming, “Hold on! Where did that fancy-looking structure come from?” They arise because proteins are not just long chains of amino acids. They actually bend and change shape. The shape they take depends on several factors, including:
Amino acid composition
pH of environment
Temperature of environment
Cellular machinery
Random molecular movements
The composition, shape, and organization of proteins make up their biomolecular structure.
The Essay
And last, but certainly not least, we come to the essay.
Why not chapter or book? Well, simply put, we need a good place to stop this metaphor. So let’s recap:
DNA acts as the alphabet, coding for amino acids in codons.
These codons act as words to make proteins.
These proteins act as sentences, and merge together to make larger structures.
These larger structures are your paragraphs.
Scientists call the process of going from DNA to protein transcription and translation. In next week’s blog post, we’ll cover the actual mechanics of how these processes work.
So what are your thoughts? Did you like the metaphor of language? Or would you prefer a different metaphor? Let us know in the comments.
https://www.crigenetics.com/blog/the-language-of-dna
1. The origin of the genetic cipher
1.Triplet codons must be assigned to amino acids to establish a genetic cipher. Nucleic-acid bases and amino acids don’t recognize each other directly but have to deal via chemical intermediaries ( tRNA's and Aminoacyl tRNA synthetase ), there is no obvious reason why particular triplets should go with particular amino acids.
2. Other translation assignments are conceivable, but whatever cipher is established, the right amino acids must be assigned to permit polypeptide chains, which fold to active functional proteins. Functional amino acid chains in sequence space are rare. There are two possibilities to explain the correct assignment of the codons to the right amino acids. Chance, and design. Natural selection is not an option, since DNA replication is not set up at the stage prior to a self-replicating cell, but this assignment had to be established before.
3. If it were a lucky accident that happened by chance, luck would have hit the jackpot through trial and error amongst 1.5 × 10^84 possible genetic code tables. That is the number of atoms in the whole universe. That puts any real possibility of a chance of providing the feat out of question. Its, using Borel's law, in the realm of impossibility. Natural selection would have to evaluate roughly 10^55 codes per second to find the one that's universal. Put simply, the chemical lottery lacks the time necessary to find the universal genetic code.
4. We have not even considered that there are also over 500 possible amino acids, which would have to be sorted out, to get only 20, and select all L amino and R sugar bases......
5. We know that minds do invent languages, codes, translation systems, ciphers, and complex, specified information all the time.
6. Put it in other words: The task compares to invent two languages, two alphabets, and a translation system, and the information content of a book ( for example hamlet) being created and written in English, and translated to Chinese, through the invention and application of an extremely sophisticated hardware system.
7. The genetic code and its translation system are best explained through the action of an intelligent designer.


https://reasonandscience.catsboard.com/t1472-the-language-of-the-genetic-code
The word language is from Vulgar Latin *linguaticum, from Latin lingua "tongue," also "speech, language," from PIE root *dnghu- "tongue." Speaking is translated, parlare in Italian, or From Vulgar Latin parolāre, back formation of Late Latin paravola, from Latin parabola (“comparison”), from Ancient Greek παραβολή (parabolḗ). παραβολή • (parabolḗ) f (genitive παραβολῆς); first declension a placing of two things side by side, juxtaposition. Computers nor cells do have intelligent capabilities, but in order for a computer able to host an instructional code, that can be translated, intelligent implementation is necessary. AND, this may be the key point, there are two things put side a side. On the one side, the genetic informational instruction, and on the other, the translated result, the sequence of amino acids, that are sequenced based on that instruction, using the translation mechanism, based on the genetic code. So, it is that genetic code, that makes the " putting side a side" possible. It is the essential "key". Therefore, the genetic code is indeed a language. I might not understand the meaning of codons ( as the code was only cracked in the 1960s by Nirenberg) or maybe the code or language itself has no knowledge of itself. But that is not necessary for it to function as a language, or a key, that is able to put two things side aside. So, i, as an intelligent being, am able to use language and understand what I am saying. But if there is a program, a computer code, a cipher, that is preprogrammed to exercise the transmission of information, even if not by itself conscious, it exercises a function based on implemented language, the elements that make that translation possible, are indeed a language.
Marshall Nirenburg, an American at the National Institutes of Health in Maryland, performed experiments that enabled scientists to decipher the genetic code.
MARSHALL W. NIRENBERG Will Society Be Prepared? 11 August 1967,
The genetic language now is known. and it seems clear that most, if not all, forms of life on this planet use the same language. with minor variations.
https://science.sciencemag.org/content/sci/157/3789/633.full.pdf
Complex grammar of the genomic language November 10, 2015
A new study from Sweden’s Karolinska Institutet shows that the ‘grammar’ of the human genetic code is more complex than that of even the most intricately constructed spoken languages in the world. The findings, published in the journal Nature, explain why the human genome is so difficult to decipher – and contribute to the further understanding of how genetic differences affect the risk of developing diseases on an individual level. “The genome contains all the information needed to build and maintain an organism, but it also holds the details of an individual’s risk of developing common diseases such as diabetes, heart disease and cancer”, says study lead-author Arttu Jolma, doctoral student at the Department of Biosciences and Nutrition. “If we can improve our ability to read and understand the human genome, we will also be able to make better use of the rapidly accumulating genomic information on a large number of diseases for medical benefits.”
https://health.economictimes.indiatimes.com/news/industry/complex-grammar-of-the-genomic-language/49731356
Cell Biology December 29, 2013
In the alphabet of the three letter word found in cell biology are the organic bases, which are adenine (A), guanine (G), cytosine (C) and thymine (T). It is the triplet recipe of these
bases that make up the ‘dictionary’ we call in molecular biology genetic code. The codal system enables the transmission of genetic information to be codified, which at molecular level, is conveyed through genes.
https://upload.wikimedia.org/wikipedia/commons/1/17/Cell_Biology.pdf
Bert hubert DNA seen through the eyes of a coder (or, If you are a hammer, everything looks like a nail) Jan 09 2021
The language of DNA is digital, but not binary. Where binary encoding has 0 and 1 to work with (2 - hence the 'bi'nary), DNA has 4 positions, T, C, G and A. Whereas a digital byte is mostly 8 binary digits, a DNA 'byte' (called a 'codon') has three digits. Because each digit can have 4 values instead of 2, an DNA codon has 64 possible values, compared to a binary byte which has 256.
http://ds9a.nl/amazing-dna/
Stephanie Seiler Scientists discover double meaning in genetic code December 12, 2013
Since the genetic code was deciphered in the 1960s, scientists have assumed that it was used exclusively to write information about proteins. UW scientists were stunned to discover that genomes use the genetic code to write two separate languages. One describes how proteins are made, and the other instructs the cell on how genes are controlled. One language is written on top of the other, which is why the second language remained hidden for so long.
http://www.washington.edu/news/2013/12/12/scientists-discover-double-meaning-in-genetic-code/
Sungchul Ji’s: The linguistics of DNA Mai 18, 1999
“Biologic systems and processes cannot be fully accounted for in terms of the principles and laws of physics and chemistry alone, but they require in addition the principles of semiotics—the science of symbols and signs, including linguistics.”
Ji identifies 13 characteristics of human language. DNA shares 10 of them. Cells edit DNA. Theyalso communicate with each other and literally speak a language he called “cellese,” described as “a self-organizing system of molecules, some of which encode, act as signs for, or trigger, gene-directed cell processes.” This comparison between cell language and human language is not a loosey-goosey analogy; it’s formal and literal. Human language and cell language both employ multilayered symbols. Dr. Ji explains this similarity in his paper: “Bacterial chemical conversations also include assignment of contextual meaning to words and sentences (semantic) and conduction of dialogue (pragmatic)—the fundamental aspects of linguistic communication.” This is true of genetic material. Signals between cells do this as well.*
“The Linguistics of DNA: Words, Sentences, Grammar, Phonetics, and Semantics”
https://www.academia.edu/33579512/The_Linguistics_of_DNA_Words_Sentences_Grammar_Phonetics_and_Semantics
Vladimir I.shCherbak The “Wow! signal” of the terrestrial genetic code May 2013
In case that there was any doubt about the intelligent origin of DNA, here it is from " Science Direct ";
"Here we show that the terrestrial code displays a thorough precision-type orderliness matching the criteria to be considered an informational signal. Simple arrangements of the code reveal an ensemble of arithmetical and ideographical patterns of the same symbolic language. Accurate and systematic, these underlying patterns appear as a product of precision logic and nontrivial computing rather than of stochastic processes (the null hypothesis that they are due to chance coupled with presumable evolutionary pathways is rejected with P-value < 10–13). The patterns are profound to the extent that the code mapping itself is uniquely deduced from their algebraic representation. The signal displays readily recognizable hallmarks of artificiality, among which are the symbol of zero, the privileged decimal syntax and semantical symmetries. Besides, extraction of the signal involves logically straightforward but abstract operations, making the patterns essentially irreducible to any natural origin.
http://www.sciencedirect.com/science/article/pii/S0019103513000791
Stephen C. Meyer, Signature in the cell :
Crick later developed this idea in his famous “sequence hypothesis,” according to which the chemical parts of DNA (the nucleotide bases) function like letters in a written language or symbols in a computer code. Just as letters in an English sentence or digital characters in a computer program may convey information depending on their arrangement, so too do certain sequences of chemical bases along the spine of the DNA molecule convey precise instructions for building proteins. Like the precisely arranged zeros and ones in a computer program, the chemical bases in DNA convey information in virtue of their “specificity.” As Richard Dawkins notes, “The machine code of the genes is uncannily computer-like.”3 Software developer Bill Gates goes further: “DNA is like a computer program but far, far more advanced than any software ever created.” What the other scientists did dispute was a controversial new hypothesis that Thaxton and his colleagues had floated in the epilogue of their book in an attempt to explain the DNA enigma. They had suggested that the information in DNA might have originated from an intelligent source or, as they put it, an “intelligent cause.” Since, in our experience, information arises from an intelligent source, and since the information in DNA was, in their words, “mathematically identical” to the information in a written language or computer code, they suggested that the presence of information in DNA pointed to an intelligent cause. The code, in other words, pointed to a programmer. A system or sequence of characters manifests “sequence specificity” if the function of the system as a whole depends upon the specific arrangement of the parts. Language has this property. Software has this property. And so too do proteins. Human artifacts and technology—paintings, signs, written text, spoken language, ancient hieroglyphics, integrated circuits, machine codes, computer hardware and software—exhibit specified complexity; among those, software and its encoded sequences of digital characters function in a way that most closely parallels the base sequences in DNA. Thus, oddly, at nearly the same time that computer scientists were beginning to develop machine languages, molecular biologists were discovering that living cells had been using something akin to machine code34 or software35 all along. To quote the information scientist Hubert Yockey again, “The genetic code is constructed to confront and solve the problems of communication and recording by the same principles found…in modern communication and computer codes.”36 Like software, the coding regions of DNA direct operations within a complex material system via highly variable and improbable, yet also precisely specified, sequences of chemical characters. How did these digitally encoded and specifically sequenced instructions in DNA arise? And how did they arise within a channel for transmitting information? As Yockey noted, what needs explaining in biological systems is not order (in the sense of a symmetrical or repeating pattern), but information, the kind of specified digital information found in software, written languages, and DNA. The argument does not depend upon the similarity of DNA to a computer program or human language, but upon the presence of an identical feature in both DNA and intelligently designed codes, languages, and artifacts. Because we know intelligent agents can (and do) produce complex and functionally specified sequences of symbols and arrangements of matter, intelligent agency qualifies as an adequate causal explanation for the origin of this effect. Since, in addition, materialistic theories have proven universally inadequate for explaining the origin of such information, intelligent design now stands as the only entity with the causal power known to produce this feature of living systems.
Sedeer el-Showk The Language of DNA July 28, 2014
One of the striking things about the genetic code is the remarkable way it twists back on itself, combining redundancy and utility in a simple, elegant language. Many of us are introduced to the basic concept in school, but that introduction often leaves out the wrinkles — some of them newly discovered — which give the system its resilience and precision. Despite their complexity, most of these tricks are pretty easy to explain with linguistic analogies, which is precisely what I’m going to try in this post.
Four letters make up the genetic alphabet: A, T, G, and C. In one sense, a gene is nothing more than a sequence of those letters, like TTGAAGCATA…, which has a certain biological meaning or function. But what makes a series of letters have meaning, what gives it a function? In the most straightforward case, it happens because a gene is translated into a protein, a tiny molecular machine. Proteins are made of amino acids, and each gene lists the amino acids that make up a specific protein. Since there are only four genetic letters but 20 different amino acids, the information in a gene is organized into three-letter words called codons; there are only 16 ways of combining four letters into two-letter words, but bumping up the length by a single letter creates 64 possible three-letter words — more than enough to have one for each amino acid. The molecular machinery of the cell assembles a protein by reading through the appropriate gene on a strand of DNA, and stringing together the amino acids that match the codons.
The beauty of the system emerges from the fact that there are 64 possible words but they only need 21 different meanings — 20 amino acids plus a stop sign. That creates the first layer of redundancy, since codons can be synonyms. Just like ‘cup’ and ‘glass’ mean (essentially) the same thing, two different codons can refer to the same amino acid; for example, the GAG and GAA both mean ‘glutamic acid’. Synonymous codons offer some protection against mutation. If the last letter of a GAA happened to mutate into a G in a gene, it would still get a glutamic acid at that point, since GAA and GAG are synonyms.
Of course, synonymous codons don’t completely mask the effect of mutations. Continuing with the example above, if GAA mutated into GAC or GAT, the meaning of the codon would change. Instead of referring to glutamic acid, it would now refer to a different amino acid called aspartic acid. The change in amino acids would affect how the resulting protein functions, which would have consequences for the organism — it might not be able to taste a particular chemical, for example. The change would depend on what the protein normally does and on how different the new amino acid makes it, and that’s where another layer of redundancy comes in. The amino acids can be divided into groups based on important chemical properties, and codons that are similar (but not synonymous) often refer to different amino acids in the same group — that is, to amino acids with similar properties. Even though GAA/GAG and GAC/GAT refer to different amino acids, both are in the ‘polar’ group of amino acids, so the impact is less than if the switch had been to a completely different group. Our languages don’t need the same level of robustness as the genetic code, so there isn’t a similar redundancy (at least, not that I know of). It would be as though English were set up so that any typos of the word ‘cat’ would still be the name of a mammal (like ‘bat’) instead of something completely different (like ‘car’ or ‘hat’).
There’s one more wrinkle, a remarkable trick to get some extra precision out of all this redundancy. In English, synonyms often have slightly different meanings (think of ‘eat’ and ‘dine’, for example), and it turns out that synonyms in the genetic code are also subtly different. A paper published in Science last year showed that the codons at the beginning of a gene affect how strongly that gene is expressed. It’s as though someone described something as ‘a dime for twelve’ instead of ‘a dime a dozen‘; the meaning is exactly the same, but the phrase has less of an impact. Swapping GAA for GAG in a gene doesn’t affect its meaning, but if the change happens near the start of the gene it can change the activity level. (For the more technically inclined: this seems to result from changes in the secondary structure of the mRNA.) It’s an amazing trick, wringing an extra touch of utility out of a system driven by the need for resilience. These processes — the translation of DNA into proteins — are central to the story of evolution, so it’s not surprising to discover that they’ve been exquisitely honed over the aeons. It is beautiful, though.
https://www.nature.com/scitable/blog/accumulating-glitches/the_language_of_dna/
Sandor Schneider, Systems Engineer at Telecommunications
From IT point of view the DNA is a virtual machine with its own machine code. The memory addresses contain 2 bits 00,01,10,11 which are named A,G,T,C (A,G,U,C). Each 3 memory address build a machine code instruction, named “codon”. This is 6 bits. The number of possible instructions 64. The program begins with an “AUG” (methionin) entry point, and there are 3 possible exit point. Just like a computer program. Instructions can create 20 amino acids redundantly
CRI Genetics The Language of DNA 15 NOV, 2019
DNA translation: Everyone speaks a language. Animals speak a language. Computers speak a language. Even your cells speak a language. And like any language, we need to understand the basic rules before we can read and write with it. Four letters make up DNA’s alphabet. These four letters are:
Adenine (A)
Cytosine (C)
Guanine (G)
Thymine (T)
But letters alone do not make a language. I could show you a Cyrillic alphabet, and it wouldn’t mean something to you unless you can speak a Slavic language. In the same way, we need to know what the words are in DNA. Conveniently, all of DNA’s words are the same length. They are all three (3) letters long. Scientists call these three letters a codon. In the following chart, we’ll see what these codons mean.
Each codon designates an amino acid. For example, the codon TAT codes for the amino acid Tyrosine. If we continue our analogy, this makes each codon a “word.” These words are the basis of DNA translation. In DNA translation, DNA is converted into a specific sequence of amino acids. But words alone aren’t enough to convey meaning. You need to string words together to form sentences. In the same way, amino acids combine together through DNA translation to form proteins. These sentences need punctuation. Punctuation serves to let you know when a sentence begins, when it ends, and any pauses or gaps in-between. DNA is no different. It uses specific codons to indicate the beginning or ending of a sentence. For example, the codon “ATG” indicates the beginning of an amino acid sequence. For this reason, scientists refer to ATG as the “START” codon. It is always at the beginning of a sentence. Without a START codon, your cells wouldn’t know where to begin making proteins. There are also three codons that act as a “STOP” codon. These three codons (TGA, TAA, TAG) always indicate the end of a sentence. Without a STOP codon, your cells wouldn’t know when to stop making a given protein.
As a demonstration, here’s what an example of a “sentence” might look like in DNA:
ATG TAT CAG GGA TGA
This translates to:
START - Tyrosine - Glutamine - Glycine - STOP
This would produce a protein made of 3 amino acids (Tyr-Glu-Gly). Most proteins are not this short. For example, a hemoglobin subunit is 141 amino acids long.
The Paragraphs
To continue the metaphor of language, sentences aren’t the only part of a written document. Writers clump similar sentences together into paragraphs. And the same is true for proteins. Individual units of protein may come together to form something larger than themselves.
For example, take a hemoglobin molecule:

A hemoglobin molecule consists of eight subunits -- two alpha chains, two beta chains, and four heme groups. These units fold together to hold iron molecules. These iron molecules attract oxygen to hemoglobin. Now I hear you screaming, “Hold on! Where did that fancy-looking structure come from?” They arise because proteins are not just long chains of amino acids. They actually bend and change shape. The shape they take depends on several factors, including:
Amino acid composition
pH of environment
Temperature of environment
Cellular machinery
Random molecular movements
The composition, shape, and organization of proteins make up their biomolecular structure.
The Essay
And last, but certainly not least, we come to the essay.
Why not chapter or book? Well, simply put, we need a good place to stop this metaphor. So let’s recap:
DNA acts as the alphabet, coding for amino acids in codons.
These codons act as words to make proteins.
These proteins act as sentences, and merge together to make larger structures.
These larger structures are your paragraphs.
Scientists call the process of going from DNA to protein transcription and translation. In next week’s blog post, we’ll cover the actual mechanics of how these processes work.
So what are your thoughts? Did you like the metaphor of language? Or would you prefer a different metaphor? Let us know in the comments.
https://www.crigenetics.com/blog/the-language-of-dna
1. The origin of the genetic cipher
1.Triplet codons must be assigned to amino acids to establish a genetic cipher. Nucleic-acid bases and amino acids don’t recognize each other directly but have to deal via chemical intermediaries ( tRNA's and Aminoacyl tRNA synthetase ), there is no obvious reason why particular triplets should go with particular amino acids.
2. Other translation assignments are conceivable, but whatever cipher is established, the right amino acids must be assigned to permit polypeptide chains, which fold to active functional proteins. Functional amino acid chains in sequence space are rare. There are two possibilities to explain the correct assignment of the codons to the right amino acids. Chance, and design. Natural selection is not an option, since DNA replication is not set up at the stage prior to a self-replicating cell, but this assignment had to be established before.
3. If it were a lucky accident that happened by chance, luck would have hit the jackpot through trial and error amongst 1.5 × 10^84 possible genetic code tables. That is the number of atoms in the whole universe. That puts any real possibility of a chance of providing the feat out of question. Its, using Borel's law, in the realm of impossibility. Natural selection would have to evaluate roughly 10^55 codes per second to find the one that's universal. Put simply, the chemical lottery lacks the time necessary to find the universal genetic code.
4. We have not even considered that there are also over 500 possible amino acids, which would have to be sorted out, to get only 20, and select all L amino and R sugar bases......
5. We know that minds do invent languages, codes, translation systems, ciphers, and complex, specified information all the time.
6. Put it in other words: The task compares to invent two languages, two alphabets, and a translation system, and the information content of a book ( for example hamlet) being created and written in English, and translated to Chinese, through the invention and application of an extremely sophisticated hardware system.
7. The genetic code and its translation system are best explained through the action of an intelligent designer.


Last edited by Otangelo on Sun Aug 13, 2023 8:29 pm; edited 14 times in total