DNA Replication in eukaryotes
DNA replication in prokaryotes, overview
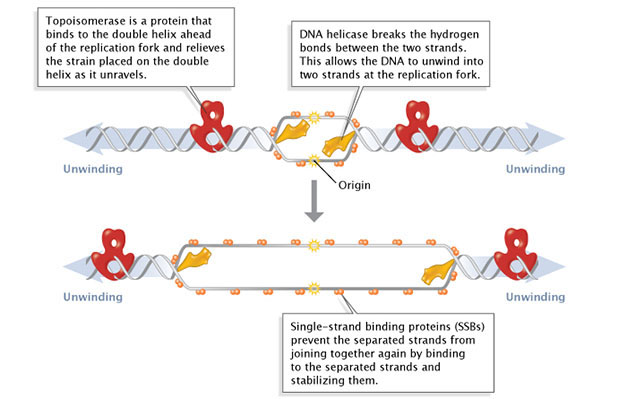
Eukaryotic DNA replication is not as well understood as bacterial replication. Much research has been carried out on a v ariety of experimental organisms, particularly yeast and mammalian cells. Many of these studies have found extensive similarities between the general features of DNA replication in prokaryotes and eukaryotes. For example, DNA helicases, topoisomerases, single-strand binding proteins, primases, DNA polymerases, and DNA ligases. Nevertheless, at the molecular level, eukaryotic DNA replication appears to be substantially more complex. These additional intricacies of eukaryotic DNA replication are related to several features of eukaryotic cells. In particular, eukaryotic cells have larger, linear chromosomes, the chromatin is tightly packed within nucleosomes, and cell cycle regulation is much more complicated. This section emphasizes some of the unique features of eukaryotic DNA replication.
Initiation Occurs at Multiple Origins of Replication on Linear Eukaryotic Chromosomes
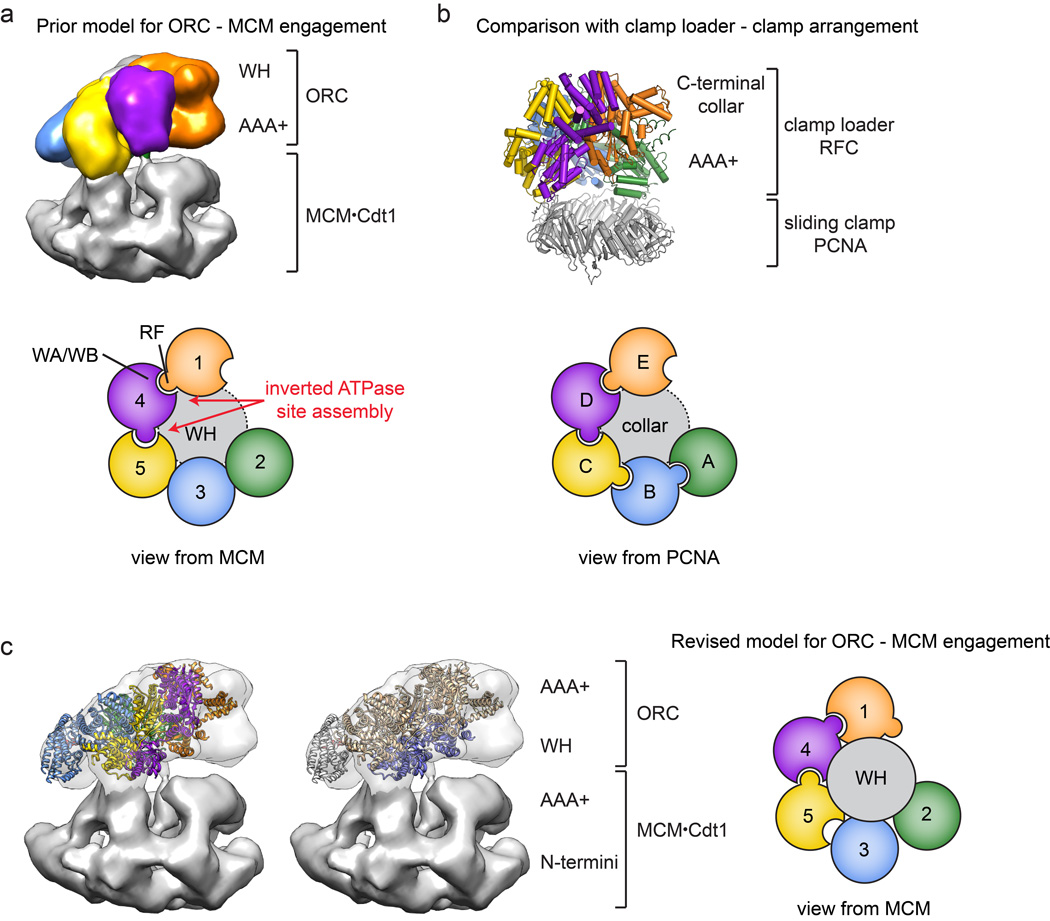
Because eukaryotes have long, linear chromosomes, the chromosomes require multiple origins of replication so the DNA can be replicated in a reasonable length of time. In 1968, Joel Huberman and Arthur Riggs provided evidence for multiple origins of replication by adding a radiolabeled nucleoside (3H-thymidine) to a culture of actively dividing cells, followed by a chase with nonlabeled thymidine. The radiolabeled thymidine was taken up by the cells and incorporated into their newly made DNA strands for a brief period. The chromosomes were then isolated from the cells and subjected to autoradiography. As seen in Figure 11.21 , radiolabeled segments were interspersed among nonlabeled segments. This result is consistent with the hypothesis that eukaryotic chromosomes contain multiple origins of replication. As shown schematically in Figure 11.22 , DNA replication proceeds bidirectionally from many origins of replication during S phase of the cell cycle. The multiple replication forks eventually make contact with each other to complete the replication process.
The molecular features of eukaryotic origins of replication may have some similarities to the origins found in bacteria. At the molecular level, eukaryotic origins of replication have been extensively studied in the yeast Saccharomyces cerevisiae. In this organism, several replication origins have been identified and sequenced. They have been named ARS elements (for autonomously replicating sequence). ARS elements, which are about 50 bp in length, are necessary to initiate chromosome replication. ARS elements have unique features of their DNA sequences. First, they contain a higher percentage of A and T bases than the rest of the chromosomal DNA. In addition, they contain a copy of the ARS consensus sequence (ACS), ATTTAT(A or G)TTTA, along with additional elements that enhance origin function. This arrangement is similar to bacterial origins.
DNA replication in eukaryotes begins with the assembly of a prereplication complex (preRC) consisting of at least 14 different proteins. Part of the preRC is a group of six proteins called the origin recognition complex (ORC) that acts as the initiator of eukaryotic DNA replication. The ORC was originally identified in yeast as a protein complex that binds directly to ARS elements. DNA replication at the origin begins with the binding of ORC, which usually occurs during G1 phase. Other proteins of the preRC then bind, including a group of proteins called MCM helicase.
MCM is an acronym for minichromosome maintenance. The genes encoding MCM proteins were originally identified in mutant yeast strains that are defective in the maintenance of minichromosomes in the cell. MCM proteins have since been shown to play a role in DNA replication.
The binding of MCM helicase at the origin completes a process called DNA replication licensing; only those origins with MCM helicase can initiate DNA synthesis. During S phase, DNA synthesis begins when preRCs are acted on by at least 22 additional proteins that activate MCM helicase and assemble two divergent replication forks at each replication origin. An important role of these additional proteins is to carefully regulate the initiation of DNA replication so that it happens at the correct time during the cell cycle and occurs only once during the cell cycle. The precise roles of these proteins are under active research investigation.
Eukaryotes Contain Several Different DNA Polymerases
Eukaryotes have many types of DNA polymerases. For example, mammalian cells have well over a dozen different DNA polymerases (Table 11.4 ).

Four of these, designated α (alpha), ε (epsilon), δ (delta), and γ (gamma), have the primary function of replicating DNA. DNA polymerase γ functions in the mitochondria to replicate mitochondrial DNA, whereas α, ε, and δ are involved with DNA replication in the cell nucleus during S phase. DNA polymerase α is the only eukaryotic polymerase that associates with primase. The functional role of the DNA polymerase α/primase complex is to synthesize a short RNA-DNA primer of approximately 10 RNA nucleotides followed by 20 to 30 DNA nucleotides. This short RNA-DNA strand is then used by DNA polymerase ε or δ for the processive elongation of the leading and lagging strands, respectively. For this to happen, the DNA polymerase α/primase complex dissociates from the replication fork and is exchanged for DNA polymerase ε or δ. This exchange is called a polymerase switch. Accumulating evidence suggests that DNA polymerase ε is primarily involved with leading- strand synthesis, whereas DNA polymerase δ is responsible for lagging-strand synthesis. What are the functions of the other DNA polymerases? Several of them also play an important role in DNA repair. DNA polymerase β, which has been studied for several decades, is not involved in the replication of normal DNA, but plays an important role in removing incorrect bases from damaged DNA. More recently, several additional DNA polymerases have been identified. While their precise roles have not been elucidated, many of these are in a category called lesion-replicating polymerases. When DNA polymerase α, δ, and ε encounter abnormalities in DNA structure, such as abnormal bases or cross-links, they may be unable to replicate over the aberration. When this occurs, lesion-replicating polymerases are attracted to the damaged DNA and have special properties that enable them to synthesize a complementary strand over the abnormal region. Each type of lesion-replicating polymerase may be able to replicate over a different kind of DNA damage.
Flap Endonuclease Removes RNA Primers During Eukaryotic DNA Replication
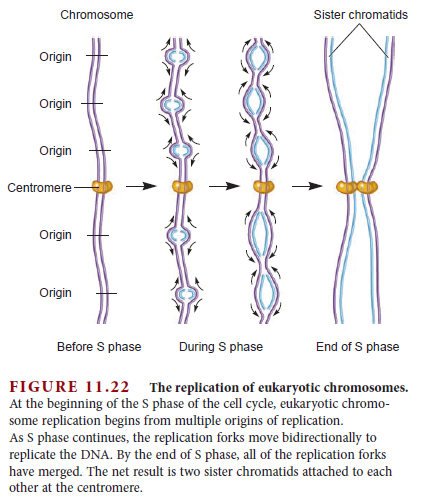
Another key difference between bacterial and eukaryotic DNA replication is the way that RNA primers are removed. Bacterial RNA primers are removed by DNA polymerase I. By comparison, a DNA polymerase enzyme does not play this role in eukaryotes. Instead, an enzyme called flap endonuclease is primarily responsible for RNA primer removal. Flap endonuclease gets its name because it removes small pieces of RNA flaps that are generated by the action of DNA polymerase δ. In the diagram shown in Figure 11.23 , DNA polymerase δ elongates the left Okazaki fragment until it runs into the RNA primer of the adjacent Okazaki fragment on the right. This causes a portion of the RNA primer to form a short flap, which is removed by the endonuclease function of flap endonuclease.
As DNA polymerase δ continues to elongate the DNA, short flaps continue to be generated, which are sequentially removed by flap endonuclease. Eventually, all of the RNA primer is removed, and DNA ligase can seal the DNA fragments together. Though flap endonuclease is thought to be the primary pathway for RNA primer removal in eukaryotes, it is unable to remove a flap that is too long. In such cases, a long flap is cleaved by the enzyme called Dna2 nuclease/helicase. This enzyme can cut a long flap, thereby generating a short flap. The short flap is then removed via flap endonuclease.
The Ends of Eukaryotic Chromosomes are Replicated by Telomerase
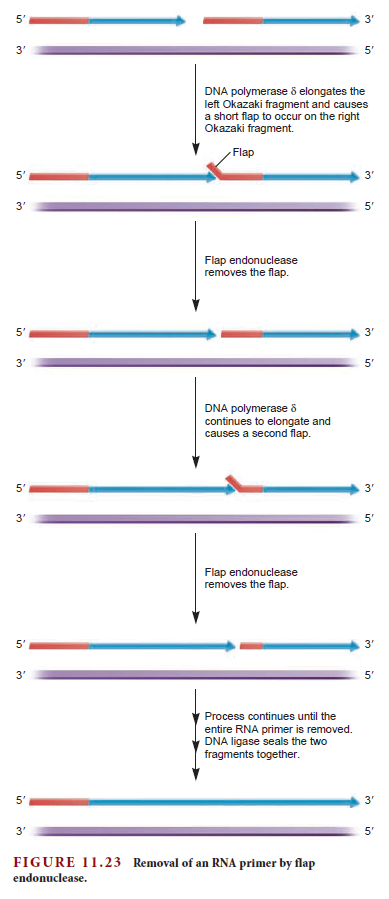
Linear eukaryotic chromosomes contain telomeres at both ends. The term telomere refers to the complex of telomeric sequences within the DNA and the special proteins that are bound to these sequences. Telomeric sequences consist of a moderately repetitive tandem array and a 3ʹ overhang region that is 12 to 16 nucleotides in length (Figure 11.24 ).
The tandem array that occurs within the telomere has been studied in a wide variety of eukaryotic organisms. A common feature is that the telomeric sequence contains several guanine nucleotides and often many thymine nucleotides (Table 11.5 ).

Depending on the species and the cell type, this sequence can be tandemly repeated up to several hundred times in the telomere region. One reason why telomeric repeat sequences are needed is because DNA polymerase is unable to replicate the 3ʹ ends of DNA strands. Why is DNA polymerase unable to replicate this region? The answer lies in the two unusual enzymatic features of this enzyme. As discussed previously, DNA polymerase synthesizes DNA only in a 5ʹ to 3ʹ direction, and it cannot link together the first two individual nucleotides; it can elongate only preexisting strands. These two features of DNA polymerase function pose a problem at the 3ʹ ends of linear chromosomes. As shown in Figure 11.25 the 3ʹ end of a DNA strand cannot be replicated by DNA polymerase because a primer cannot be made upstream from this point. Therefore, if this problem were not solved, the chromosome would become progressively shorter with each round of DNA replication.

To prevent the loss of genetic information due to chromosome shortening, additional DNA sequences are attached to the ends of telomeres. In 1984, Carol Greider and Elizabeth Blackburn discovered an enzyme called telomerase that prevents chromosome shortening. It recognizes the sequences at the ends of eukaryotic chromosomes and synthesizes additional repeats of telomeric sequences. They received the 2009 Nobel Prize in physiology or medicine for their discovery. Figure 11.26 shows the interesting mechanism by which telomerase works. The telomerase enzyme contains both protein subunits and RNA.
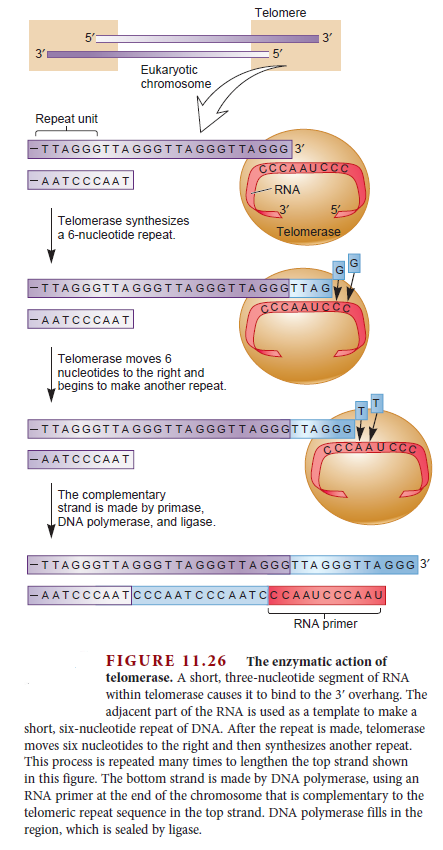
The RNA part of telomerase contains a sequence complementary to the DNA sequence found in the telomeric repeat. This allows telomerase to bind to the 3ʹ overhang region of the telomere. Following binding, the RNA sequence beyond the binding site functions as a template allowing the synthesis of a six-nucleotide sequence at the end of the DNA strand. This is called polymerization, because it is analogous to the function of DNA polymerase. It is catalyzed by two identical protein subunits called telomerase reverse transcriptase (TERT) . TERT’s name indicates that it uses an RNA template to synthesize DNA. Following polymerization, the telomerase can then move—a process called translocation—to the new end of this DNA strand and attach another six nucleotides to the end. This binding-polymerization-translocation cycle occurs many times in a row, thereby greatly lengthening the 3ʹ end of the DNA strand in the telomeric region. The complementary strand is then synthesized by primase, DNA polymerase, and DNA ligase.
DNA replication in prokaryotes, overview
Eukaryotic DNA replication is not as well understood as bacterial replication. Much research has been carried out on a v ariety of experimental organisms, particularly yeast and mammalian cells. Many of these studies have found extensive similarities between the general features of DNA replication in prokaryotes and eukaryotes. For example, DNA helicases, topoisomerases, single-strand binding proteins, primases, DNA polymerases, and DNA ligases. Nevertheless, at the molecular level, eukaryotic DNA replication appears to be substantially more complex. These additional intricacies of eukaryotic DNA replication are related to several features of eukaryotic cells. In particular, eukaryotic cells have larger, linear chromosomes, the chromatin is tightly packed within nucleosomes, and cell cycle regulation is much more complicated. This section emphasizes some of the unique features of eukaryotic DNA replication.
Initiation Occurs at Multiple Origins of Replication on Linear Eukaryotic Chromosomes
Because eukaryotes have long, linear chromosomes, the chromosomes require multiple origins of replication so the DNA can be replicated in a reasonable length of time. In 1968, Joel Huberman and Arthur Riggs provided evidence for multiple origins of replication by adding a radiolabeled nucleoside (3H-thymidine) to a culture of actively dividing cells, followed by a chase with nonlabeled thymidine. The radiolabeled thymidine was taken up by the cells and incorporated into their newly made DNA strands for a brief period. The chromosomes were then isolated from the cells and subjected to autoradiography. As seen in Figure 11.21 , radiolabeled segments were interspersed among nonlabeled segments. This result is consistent with the hypothesis that eukaryotic chromosomes contain multiple origins of replication. As shown schematically in Figure 11.22 , DNA replication proceeds bidirectionally from many origins of replication during S phase of the cell cycle. The multiple replication forks eventually make contact with each other to complete the replication process.
The molecular features of eukaryotic origins of replication may have some similarities to the origins found in bacteria. At the molecular level, eukaryotic origins of replication have been extensively studied in the yeast Saccharomyces cerevisiae. In this organism, several replication origins have been identified and sequenced. They have been named ARS elements (for autonomously replicating sequence). ARS elements, which are about 50 bp in length, are necessary to initiate chromosome replication. ARS elements have unique features of their DNA sequences. First, they contain a higher percentage of A and T bases than the rest of the chromosomal DNA. In addition, they contain a copy of the ARS consensus sequence (ACS), ATTTAT(A or G)TTTA, along with additional elements that enhance origin function. This arrangement is similar to bacterial origins.
DNA replication in eukaryotes begins with the assembly of a prereplication complex (preRC) consisting of at least 14 different proteins. Part of the preRC is a group of six proteins called the origin recognition complex (ORC) that acts as the initiator of eukaryotic DNA replication. The ORC was originally identified in yeast as a protein complex that binds directly to ARS elements. DNA replication at the origin begins with the binding of ORC, which usually occurs during G1 phase. Other proteins of the preRC then bind, including a group of proteins called MCM helicase.
MCM is an acronym for minichromosome maintenance. The genes encoding MCM proteins were originally identified in mutant yeast strains that are defective in the maintenance of minichromosomes in the cell. MCM proteins have since been shown to play a role in DNA replication.
The binding of MCM helicase at the origin completes a process called DNA replication licensing; only those origins with MCM helicase can initiate DNA synthesis. During S phase, DNA synthesis begins when preRCs are acted on by at least 22 additional proteins that activate MCM helicase and assemble two divergent replication forks at each replication origin. An important role of these additional proteins is to carefully regulate the initiation of DNA replication so that it happens at the correct time during the cell cycle and occurs only once during the cell cycle. The precise roles of these proteins are under active research investigation.
Eukaryotes Contain Several Different DNA Polymerases
Eukaryotes have many types of DNA polymerases. For example, mammalian cells have well over a dozen different DNA polymerases (Table 11.4 ).
Four of these, designated α (alpha), ε (epsilon), δ (delta), and γ (gamma), have the primary function of replicating DNA. DNA polymerase γ functions in the mitochondria to replicate mitochondrial DNA, whereas α, ε, and δ are involved with DNA replication in the cell nucleus during S phase. DNA polymerase α is the only eukaryotic polymerase that associates with primase. The functional role of the DNA polymerase α/primase complex is to synthesize a short RNA-DNA primer of approximately 10 RNA nucleotides followed by 20 to 30 DNA nucleotides. This short RNA-DNA strand is then used by DNA polymerase ε or δ for the processive elongation of the leading and lagging strands, respectively. For this to happen, the DNA polymerase α/primase complex dissociates from the replication fork and is exchanged for DNA polymerase ε or δ. This exchange is called a polymerase switch. Accumulating evidence suggests that DNA polymerase ε is primarily involved with leading- strand synthesis, whereas DNA polymerase δ is responsible for lagging-strand synthesis. What are the functions of the other DNA polymerases? Several of them also play an important role in DNA repair. DNA polymerase β, which has been studied for several decades, is not involved in the replication of normal DNA, but plays an important role in removing incorrect bases from damaged DNA. More recently, several additional DNA polymerases have been identified. While their precise roles have not been elucidated, many of these are in a category called lesion-replicating polymerases. When DNA polymerase α, δ, and ε encounter abnormalities in DNA structure, such as abnormal bases or cross-links, they may be unable to replicate over the aberration. When this occurs, lesion-replicating polymerases are attracted to the damaged DNA and have special properties that enable them to synthesize a complementary strand over the abnormal region. Each type of lesion-replicating polymerase may be able to replicate over a different kind of DNA damage.
Flap Endonuclease Removes RNA Primers During Eukaryotic DNA Replication
Another key difference between bacterial and eukaryotic DNA replication is the way that RNA primers are removed. Bacterial RNA primers are removed by DNA polymerase I. By comparison, a DNA polymerase enzyme does not play this role in eukaryotes. Instead, an enzyme called flap endonuclease is primarily responsible for RNA primer removal. Flap endonuclease gets its name because it removes small pieces of RNA flaps that are generated by the action of DNA polymerase δ. In the diagram shown in Figure 11.23 , DNA polymerase δ elongates the left Okazaki fragment until it runs into the RNA primer of the adjacent Okazaki fragment on the right. This causes a portion of the RNA primer to form a short flap, which is removed by the endonuclease function of flap endonuclease.
As DNA polymerase δ continues to elongate the DNA, short flaps continue to be generated, which are sequentially removed by flap endonuclease. Eventually, all of the RNA primer is removed, and DNA ligase can seal the DNA fragments together. Though flap endonuclease is thought to be the primary pathway for RNA primer removal in eukaryotes, it is unable to remove a flap that is too long. In such cases, a long flap is cleaved by the enzyme called Dna2 nuclease/helicase. This enzyme can cut a long flap, thereby generating a short flap. The short flap is then removed via flap endonuclease.
The Ends of Eukaryotic Chromosomes are Replicated by Telomerase
Linear eukaryotic chromosomes contain telomeres at both ends. The term telomere refers to the complex of telomeric sequences within the DNA and the special proteins that are bound to these sequences. Telomeric sequences consist of a moderately repetitive tandem array and a 3ʹ overhang region that is 12 to 16 nucleotides in length (Figure 11.24 ).
The tandem array that occurs within the telomere has been studied in a wide variety of eukaryotic organisms. A common feature is that the telomeric sequence contains several guanine nucleotides and often many thymine nucleotides (Table 11.5 ).
Depending on the species and the cell type, this sequence can be tandemly repeated up to several hundred times in the telomere region. One reason why telomeric repeat sequences are needed is because DNA polymerase is unable to replicate the 3ʹ ends of DNA strands. Why is DNA polymerase unable to replicate this region? The answer lies in the two unusual enzymatic features of this enzyme. As discussed previously, DNA polymerase synthesizes DNA only in a 5ʹ to 3ʹ direction, and it cannot link together the first two individual nucleotides; it can elongate only preexisting strands. These two features of DNA polymerase function pose a problem at the 3ʹ ends of linear chromosomes. As shown in Figure 11.25 the 3ʹ end of a DNA strand cannot be replicated by DNA polymerase because a primer cannot be made upstream from this point. Therefore, if this problem were not solved, the chromosome would become progressively shorter with each round of DNA replication.
To prevent the loss of genetic information due to chromosome shortening, additional DNA sequences are attached to the ends of telomeres. In 1984, Carol Greider and Elizabeth Blackburn discovered an enzyme called telomerase that prevents chromosome shortening. It recognizes the sequences at the ends of eukaryotic chromosomes and synthesizes additional repeats of telomeric sequences. They received the 2009 Nobel Prize in physiology or medicine for their discovery. Figure 11.26 shows the interesting mechanism by which telomerase works. The telomerase enzyme contains both protein subunits and RNA.
The RNA part of telomerase contains a sequence complementary to the DNA sequence found in the telomeric repeat. This allows telomerase to bind to the 3ʹ overhang region of the telomere. Following binding, the RNA sequence beyond the binding site functions as a template allowing the synthesis of a six-nucleotide sequence at the end of the DNA strand. This is called polymerization, because it is analogous to the function of DNA polymerase. It is catalyzed by two identical protein subunits called telomerase reverse transcriptase (TERT) . TERT’s name indicates that it uses an RNA template to synthesize DNA. Following polymerization, the telomerase can then move—a process called translocation—to the new end of this DNA strand and attach another six nucleotides to the end. This binding-polymerization-translocation cycle occurs many times in a row, thereby greatly lengthening the 3ʹ end of the DNA strand in the telomeric region. The complementary strand is then synthesized by primase, DNA polymerase, and DNA ligase.
Last edited by Admin on Tue 8 Dec 2015 - 13:06; edited 11 times in total