

The different genetic codes
https://reasonandscience.catsboard.com/t2277-the-different-genetic-codes
Jonathan Wells, Paul Nelson, Rhetoric and Public Affairs, November 1998: Dobzhansky believed that the common ancestry of all living things could be seen in the universality of the genetic code. This was the basis of his claim that “all organisms, no matter how diverse in other respects, conserve the basic features of the primordial life.” But we now know that the genetic code is not universal. Thomas Fox reported in 1985 that “some ‘real’ exceptions have come to light” in bacteria and single-celled organisms, “and the notion of universality will have to be discarded.” The number of exceptions has grown since then; a 1995 review noted that “a relatively high incidence of non-universal codes has been discovered … widely distributed in various groups of organisms.” The non-universality of the genetic code suggests that living things may well have had multiple origins. – 2
Steve Meyer, Signature in the Cell, page 201: The discovery of thirty-three variant genetic codes indicates that the chemical properties of the relevant monomers allow more than a single set of codon–amino acid assignments. The conclusion is straightforward: the chemical properties of amino acids and nucleotides do not determine a single universal genetic code; since there is not just one code, “it” cannot be inevitable. The codon–amino acid relationships that define the code are established and mediated by the catalytic action of some twenty separate proteins, the so-called aminoacyl-tRNA synthetases (one for each tRNA anticodon and amino-acid pair). Each of these proteins recognizes a specific amino acid and the specific tRNA with its corresponding anticodon and helps attach the appropriate amino acid to that tRNA molecule. Thus, instead of the code reducing to a simple set of chemical affinities between a small number of monomers, biochemists have found a functionally interdependent system of highly specific biopolymers, including mRNA, twenty specific tRNAs, and twenty specific synthetase proteins, each of which is itself constructed via information encoded on the very DNA that it helps to decode. This is an integrated complex system. To claim that deterministic chemical affinities made the origin of this system inevitable lacks empirical foundation. Given a pool of the bases necessary to tRNA and mRNA, given all necessary sugars and phosphates and all twenty amino acids used in proteins, would the molecules comprising the current translation system, let alone any particular genetic code, have had to arise? Indeed, would even a single synthetase have had to arise from a pool of all the necessary amino acids? Again, clearly not.
The National Center for Biotechnology Information (NCBI), currently acknowledges nineteen different coding languages for DNA. And i list 31 different ones.
Dawkins: The Greatest Show On Earth (2009, p. 409): Any mutation in the genetic code itself (as opposed to mutations in the genes that it encodes) would have an instantly catastrophic effect, not just in one place but throughout the whole organism. If any word in the 64-word dictionary changed its meaning, so that it came to specify a different amino acid, just about every protein in the body would instantaneously change, probably in many places along its length. Unlike an ordinary mutation…this would spell disaster. (2009, p. 409-10)
https://www.amazon.com/Greatest-Show-Earth-Evidence-Evolution/dp/1416594795
Dr. Jay L. Wile (2016):However, the eukaryotic cells that eventually evolved into vertebrates must have formed when a cell that used the “universal” code engulfed a cell that used yet another different code. As a result, invertebrates must have evolved from one line of eukaryotic cells, while vertebrates must have evolved from a completely separate line of eukaryotic cells. But this isn’t possible, since evolution depends on vertebrates evolving from invertebrates. Now, of course, this serious problem can be solved by assuming that while invertebrates evolved into vertebrates, their mitochondria also evolved to use a different genetic code. However, I am not really sure how that would be possible. After all, the invertebrates spent millions of years evolving, and through all those years, their mitochondrial DNA was set up based on one code. How could the code change without destroying the function of the mitochondria? At minimum, this adds another task to the long, long list of unfinished tasks necessary to explain how evolution could possibly work. Along with explaining how nuclear DNA can evolve to produce the new structures needed to change invertebrates into vertebrates, proponents of evolution must also explain how, at the same time, mitochondria can evolve to use a different genetic code! In the end, it seems to me that this wide variation in the genetic code deals a serious blow to the entire hypothesis of common ancestry, at least the way it is currently constructed. Perhaps that’s why I hadn’t heard about it until reading Dr. Rossiter’s excellent book.
http://blog.drwile.com/?p=14280
Bye-bye common ancestry !!
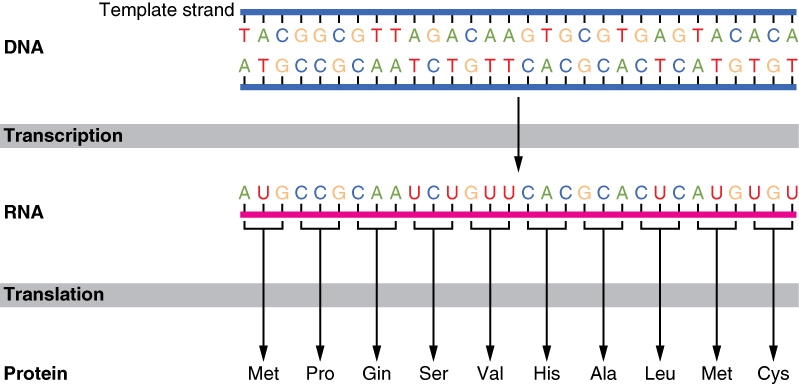
The basic process by which proteins are made in a cell. (click for credit)
I am still reading Shadow of Oz by Dr. Wayne Rossiter, and I definitely plan to post a review of it when I am finished. However, I wanted to write a separate blog post about one point that he makes in Chapter 6, which is entitled “Biological Evolution.” [url=https://books.google.com/books?id=kuwmCwAAQBAJ&pg=PT108&lpg=PT108&dq="To+date,+the+National+Center+for+Biotechnology+Information+%28NCBI%29,+which+houses+all+published+DNA+sequences"&source=bl&ots=y3djhymXWq&sig=SSjcioRSaQEZcuSGiztSRGYrJIw&hl=en&sa=X&ved=0ahUKEwjelt-frrPKAhWISCYKHSuJD9UQ6AEIHjAA#v=onepage&q="To date%2C the National Center for Biotechnology Information %28NCBI%29%2C which houses all published DNA]He says[/url]:
He then references this page from the NCBI website.
This was a shock to me. As an impressionable young student at the University of Rochester, I was taught quite definitively that there is only one code for DNA, and it is universal. This, of course, is often cited as evidence for evolution. Consider, for example, this statement from The Biology Encyclopedia:
Dr. Rossiter points out that this isn’t anywhere close to correct, and it presents serious problems for the idea that all life descended from a single, common ancestor.
To understand the importance of Dr. Rossiter’s point, you need to know how a cell makes proteins. The basic steps of the process are illustrated in the image at the top of this post. The “recipe” for each protein is stored in DNA, and it is coded by four different nucleotide bases (abbreviated A, T, G, and C). That “recipe” is copied to a different molecule, RNA, in a process called transcription. During that process, the nucleotide base “U” is used instead of “T,” so the copy has A, U, G, and C as its four nucleotide bases. The copy then goes to the place where the proteins are actually made, which is called the ribosome. The ribosome reads the recipe in units called codons. Each codon, which consists of three nucleotide bases, specifies a particular amino acid. When the amino acids are strung together in the order given by the codons, the proper protein is made. The genetic code tells the cell which codon specifies which amino acid. Look, for example, at the illustration at the top of the page. The first codon in the RNA “recipe” is AUG. According to the supposedly universal genetic code, those three nucleotide bases in that order are supposed to code for one specific amino acid:methionine (abbreviated as “Met” in the illustration). The next codon (CCG) is supposed to code for the amino acid proline (abbreviated as Pro). Each possible three-letter sequence (each possible codon) codes for a specific amino acid, and the collection of all those possible codons and what they code for is often called the genetic code.
Now, once again, according to The Biology Encyclopedia (and many, many other sources), the genetic code is nearly universal. Aside from a few minor exceptions, all organisms use the same genetic code, and that points strongly to the idea that all organisms evolved from a common ancestor. However, according to the NCBI, that isn’t even close to correct. There are all sorts of exceptions to this “universal” genetic code, and I would think that some of them result in serious problems for the hypothesis of evolution. Consider, for example, the vertebrate mitochondrial code and the invertebrate mitochondrial code. In case you didn’t know, many cells actually have two sources of DNA. The main source of DNA is in the cell’s nucleus, so it is called nuclear DNA. However, the kinds of cells that make up vertebrates (animals with backbones) and invertebrates (animals without backbones) also have DNA in their mitochondria, small structures that are responsible for making most of the energy the cell uses to survive. The DNA found in mitochondria is called mitochondrial DNA. Now, according to the hypothesis of evolution, the kinds of cells that make up vertebrates and invertebrates (called eukaryotic cells) were not the first to evolve. Instead, the kinds of cells found in bacteria (called prokaryotic cells) supposedly evolved first. Then, at a later time, one prokaryotic cell supposedly engulfed another, but the engulfed cell managed to survive. Over generations, these two cells somehow managed to start working together, and the engulfed cell became the mitochondrion for the cell that engulfed it. This is the hypothesis of endosymbiosis, and despite its many, many problems, it is the standard tale of how prokaryotic cells became eukaryotic cells. However, if the mitochondria in invertebrates use a different genetic code from the mitochondria in vertebrates, and both of those codes are different from the “universal” genetic code, what does that tell us? It means that the eukaryotic cells that eventually evolved into invertebrates must have formed when a cell that used the “universal” code engulfed a cell that used a different code. However, the eukaryotic cells that eventually evolved into vertebrates must have formed when a cell that used the “universal” code engulfed a cell that used yet another different code. As a result, invertebrates must have evolved from one line of eukaryotic cells, while vertebrates must have evolved from a completely separate line of eukaryotic cells. But this isn’t possible, since evolution depends on vertebrates evolving from invertebrates. Now, of course, this serious problem can be solved by assuming that while invertebrates evolved into vertebrates, their mitochondria also evolved to use a different genetic code. However, I am not really sure how that would be possible. After all, the invertebrates spent millions of years evolving, and through all those years, their mitochondrial DNA was set up based on one code. How could the code change without destroying the function of the mitochondria? At minimum, this adds another task to the long, long list of unfinished tasks necessary to explain how evolution could possibly work. Along with explaining how nuclear DNA can evolve to produce the new structures needed to change invertebrates into vertebrates, proponents of evolution must also explain how, at the same time, mitochondria can evolve to use a different genetic code!
In the end, it seems to me that this wide variation in the genetic code deals a serious blow to the entire hypothesis of common ancestry, at least the way it is currently constructed. Perhaps that’s why I hadn’t heard about it until reading Dr. Rossiter’s excellent book.
http://blog.drwile.com/?p=14280
There are variants of the standard genetic code. These variants are used for instance in the mitochondria of many species, and they consist in the modification of one or several codons of the standard genetic code.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2909233/
Richard Dawkins has claimed that the genetic code is universal across all organisms on earth. This is “near-conclusive proof,” he writes, that every living thing on this planet “descended from a single common ancestor” (1986, p. 270) at the root of Darwin’s universal tree of life. More recently, Dawkins repeated the claim in his bestseller The Greatest Show On Earth (2009, p. 409):
…the genetic code is universal, all but identical across animals, plants, fungi, bacteria, archaea and viruses. The 64-word dictionary, by which three letter DNA words are translated into 20 amino acids and one punctuation mark, which means ‘start reading here’ or ‘stop reading here,’ is the same 64-word dictionary wherever you look in the living kingdoms (with one or two exceptions too minor to undermine the generalization).
Let’s look at the reason Dawkins gives for why the code must be universal:
The reason is interesting. Any mutation in the genetic code itself (as opposed to mutations in the genes that it encodes) would have an instantly catastrophic effect, not just in one place but throughout the whole organism. If any word in the 64-word dictionary changed its meaning, so that it came to specify a different amino acid, just about every protein in the body would instantaneously change, probably in many places along its length. Unlike an ordinary mutation…this would spell disaster. (2009, p. 409-10)
And now, see here:
https://www.ncbi.nlm.nih.gov/Taxonomy/taxonomyhome.html/index.cgi?chapter=cgencodes
Simple counting question: does “one or two” equal 33? That’s the number of known variant genetic codes compiled by the National Center for Biotechnology Information (NCBI). By any measure, Dawkins is off by an order of magnitude.
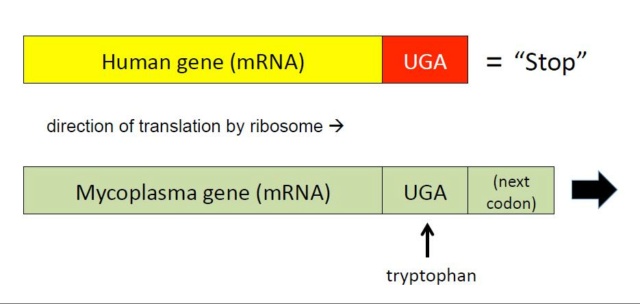
In human cells, the codon UGA codes for “stop,” meaning the end of an open reading frame (i.e., section of DNA coding for a protein). When the ribosome, the molecular machine that constructs proteins, encounters UGA in the messenger RNA of a human cell, it ceases translation. Not so in Mycoplasma, where UGA codes for the amino acid tryptophan. On encountering UGA in an mRNA strand, the Mycoplasma ribosome would insert a tryptophan (in the protein the ribosome is assembling) and keep chugging right along with translation, through the following codons, until it met a Mycoplasma stop codon. Human and Mycoplasma cells do not read their DNA in the same way.
We must bear in mind that most non-canonical codes evolved independently from the others, and so may have evolved through different steps
My comment: It is evident why the authors make that claim. As Dawkins wrote: Any mutation in the genetic code itself (as opposed to mutations in the genes that it encodes) would have an instantly catastrophic effect, not just in one place but throughout the whole organism. If any word in the 64-word dictionary changed its meaning, so that it came to specify a different amino acid, just about every protein in the body would instantaneously change, probably in many places along its length. Unlike an ordinary mutation…this would spell disaster.
And Dr.Wile: Someone can assume that while invertebrates evolved into vertebrates, their mitochondria also evolved to use a different genetic code. However, I am not really sure how that would be possible. After all, the invertebrates spent millions of years evolving, and through all those years, their mitochondrial DNA was set up based on one code. How could the code change without destroying the function of the mitochondria? At minimum, this adds another task to the long, long list of unfinished tasks necessary to explain how evolution could possibly work.
Even in a genome that has only 30-50 proteins, each protein is very long and uses the same amino acid multiple times. It would have to be shown how it is possible for four codons to go completely out of use. Then, how they can get reassigned in order to go from the “universal” code to the vertebrate mitochondrial code. Also, how did this happened only at the base of the vertebrate tree?
Why alternative genetic codes?
One reason why there are alternative genetic codes is the reduction of the number of tRNA needed. Furthermore, one alternative genetic code (the 'Echinoderm and Flatworm Mitochondrial Code') that seems to be better at reducing mutation and translation loads, and particularly yields better translation load except for very small AT content (approx. 20% AT content or less).
Of course, science literature claims that there was an adaptive advantage and improvement of fitness of these alternative codes, but how the transition could have happened is an open question.
The implications are significant: If the origin of the universal genetic code is an enigma, imagine another 33 different ones, that had to emerge independently !!!! This is simply evidence that the best explanation is an intelligent designer which created and generated different codes for different life forms separately. And it means, that the tree of life is bunk.
Since 1985 molecular biologists have discovered 33 different genetic codes in various species. Many of these are significantly different from the standard code. For example, the standard code has three different mRNA stop codons: UGA, UAA, and UAG . (A “stop codon” tells the cell to stop building-the protein is complete.) However, some variant codes have only one stop codon, UGA. The other “universal” stop codons now code for the amino acid glutamine. It’s very hard to see how an organism could have survived a transformation from the standard code to this one. Changing to this new code would cause the cell to produce useless strings of extra amino acids when it should have stopped protein production.
https://uncommondescent.com/evolution/there-are-now-many-variants-of-the-universal-genetic-code/
The Mechanisms of Codon Reassignments in Mitochondrial Genetic Codes 17 April 2006
If a change in the translation system occurs in an organism such that a codon is reassigned, most of the occurrences of this codon will still be at places where the old amino acid was preferred. We would expect the changes causing the codon reassignment to be strongly disadvantageous and to be eliminated by selection.
My comment: A reassignment means, that the tRNA's amino acid binding site would have to change to reassign a different amino acid.
The structural basis of the genetic code: amino acid recognition by aminoacyl-tRNA synthetases 28 July 2020 3
One of the most profound open questions in biology is how the genetic code was established. The correct read-out of genetic information is a delicate interplay between the composition of the binding site, non-covalent interactions, error correction mechanisms, and steric effects.
A glimpse into nature's looking glass -- to find the genetic code is reassigned: Stop codon varies widely 4
We were surprised to find that an unprecedented number of bacteria in the wild possess these codon reassignments, from "stop" to amino-acid encoding "sense," up to 10 percent of the time in some environments," said Rubin.
Another observation the researchers made was that beyond bacteria, these reassignments were also happening in phage, viruses that attack bacterial cells. Phage infect bacteria, injecting their DNA into the cell and exploiting the translational machinery of the cell to create more of themselves, to the point when the bacterial cell explodes, releasing more progeny phage particles to spread to neighboring bacteria and run amok.
The genetic translation system provides objective physical evidence of the first irreducible organic system on earth, and from it, all other organic systems follow. Moreover, this system is not the product of Darwinian evolution. Instead, it is the source of evolution (i.e. the physical conditions that enable life’s capacity to change and adapt over time) and as the first instance of specification on earth, it marks the rise of the genome and the starting point of heredity.
It is possible for mutations to cause disappearance of the codon in its original positions and reappearance in positions where the new amino acid is preferred. Mutations throughout the genome are required for it to readjust to the change in the genetic code. The problem is therefore to understand how codon reassignments can become fixed in a population despite being apparently deleterious in the intermediate stage before the genome has time to readjust.
There Are Now Many Variants Of The “Universal” Genetic Code June 13, 2018
Since 1985 molecular biologists have discovered at least 18 different genetic codes in various species.13 Many of these are significantly different from the standard code.14 For example, the standard code has three different mRNA stop codons: UGA, UAA, and UAG . (A “stop codon” tells the cell to stop building-the protein is complete.) However, some variant codes have only one stop codon, UGA. The other “universal” stop codons now code for the amino acid glutamine. It’s very hard to see how an organism could have survived a transformation from the standard code to this one. Changing to this new code would cause the cell to produce useless strings of extra amino acids when it should have stopped protein production.
https://uncommondescent.com/evolution/there-are-now-many-variants-of-the-universal-genetic-code/
Different genetic codes are strong evidence that they were designed.
Craig Venter vs Richard Dawkins:
It’s instructive to watch a fascinating exchange between Dawkins and genome guru J. Craig Venter, which occurred during a science forum held at Arizona State University. The question for discussion at the forum was “What is life?” Most of the panelists agreed that all organisms on Earth represent a single kind of life — a sample of one — because all organisms have descended from a last universal common ancestor (LUCA). This “sample of one” problem is strong motivation, panelist and NASA scientist Chris McKay argued, for exploring Mars and other planets (or their moons) in our solar system, to try to find a second example of life, unrelated to Earth organisms.
Venter disagreed — in a remarkable way (start at the 9:00 minute mark). “I’m not so sanguine as some of my colleagues here,” he said, “that there’s only one life form on this planet. We have a lot of different types of metabolism, different organisms. I wouldn’t call you [Venter said, turning to physicist Paul Davies, on his right] the same life form as the one we have that lives in pH 12 base, that would dissolve your skin if we dropped you in it.”
“Well, I’ve got the same genetic code,” said Davies. “We’ll have a common ancestor.”
“You don’t have the same genetic code,” replied Venter. “In fact, the Mycoplasmas [a group of bacteria Venter and his team have used to engineer synthetic chromosomes] use a different genetic code that would not work in your cells. So there are a lot of variations on the theme…”
Here Davies, a bit alarmed, interrupts Venter: “But you’re not saying it [i.e., Mycoplasma] belongs to a different tree of life from me, are you?”
“The tree of life is an artifact of some early scientific studies that aren’t really holding up…So there is not a tree of life.”
Dawkins is Flabbergasted
Fast forward to 11:23, when moderator Roger Bingham turns the microphone over to Dawkins:
“I’m intrigued,” replies Dawkins, “at Craig saying that the tree of life is a fiction. I mean…the DNA code of all creatures that have ever been looked at is all but identical.”
WHOPPER. Venter just told the forum that Mycoplasma read their DNA using a different coding convention than other organisms (for “stop” and tryptophan). But Dawkins is undaunted:
“Surely that means,” he asks Venter, “that they’re all related? Doesn’t it?”
As nearly as we can tell from the video, Venter only smiles.
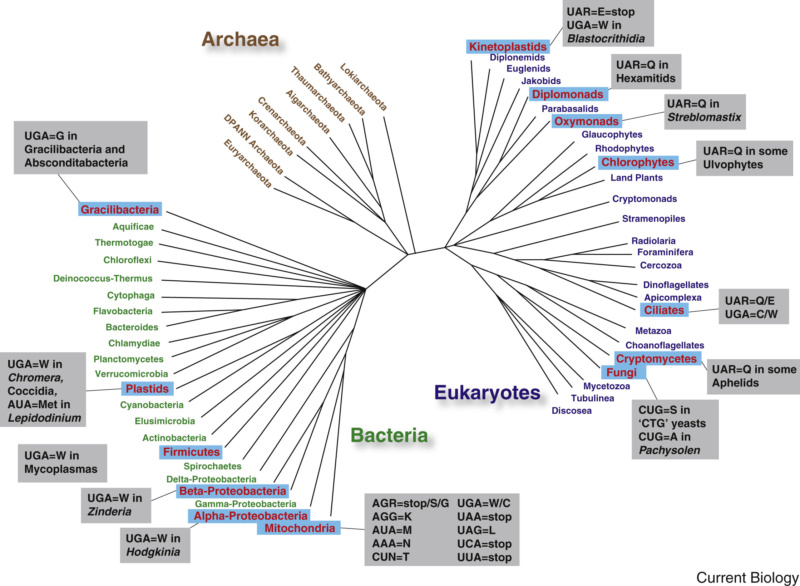
https://www.sciencedirect.com/science/article/pii/S0960982216309174
2. https://uncommondescent.com/evolution/there-are-now-many-variants-of-the-universal-genetic-code/
https://www.youtube.com/watch?v=xIHMnD2FDeY
1. https://sci-hub.st/https://www.sciencedirect.com/science/article/pii/S0960982216309174
2. https://www.sciencedirect.com/journal/biosystems/vol/164/suppl/C
3. https://www.nature.com/articles/s41598-020-69100-0
4. https://www.sciencedaily.com/releases/2014/05/140522141422.htm
5. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1894752/
https://reasonandscience.catsboard.com/t2277-the-different-genetic-codes
Jonathan Wells, Paul Nelson, Rhetoric and Public Affairs, November 1998: Dobzhansky believed that the common ancestry of all living things could be seen in the universality of the genetic code. This was the basis of his claim that “all organisms, no matter how diverse in other respects, conserve the basic features of the primordial life.” But we now know that the genetic code is not universal. Thomas Fox reported in 1985 that “some ‘real’ exceptions have come to light” in bacteria and single-celled organisms, “and the notion of universality will have to be discarded.” The number of exceptions has grown since then; a 1995 review noted that “a relatively high incidence of non-universal codes has been discovered … widely distributed in various groups of organisms.” The non-universality of the genetic code suggests that living things may well have had multiple origins. – 2
Steve Meyer, Signature in the Cell, page 201: The discovery of thirty-three variant genetic codes indicates that the chemical properties of the relevant monomers allow more than a single set of codon–amino acid assignments. The conclusion is straightforward: the chemical properties of amino acids and nucleotides do not determine a single universal genetic code; since there is not just one code, “it” cannot be inevitable. The codon–amino acid relationships that define the code are established and mediated by the catalytic action of some twenty separate proteins, the so-called aminoacyl-tRNA synthetases (one for each tRNA anticodon and amino-acid pair). Each of these proteins recognizes a specific amino acid and the specific tRNA with its corresponding anticodon and helps attach the appropriate amino acid to that tRNA molecule. Thus, instead of the code reducing to a simple set of chemical affinities between a small number of monomers, biochemists have found a functionally interdependent system of highly specific biopolymers, including mRNA, twenty specific tRNAs, and twenty specific synthetase proteins, each of which is itself constructed via information encoded on the very DNA that it helps to decode. This is an integrated complex system. To claim that deterministic chemical affinities made the origin of this system inevitable lacks empirical foundation. Given a pool of the bases necessary to tRNA and mRNA, given all necessary sugars and phosphates and all twenty amino acids used in proteins, would the molecules comprising the current translation system, let alone any particular genetic code, have had to arise? Indeed, would even a single synthetase have had to arise from a pool of all the necessary amino acids? Again, clearly not.
The National Center for Biotechnology Information (NCBI), currently acknowledges nineteen different coding languages for DNA. And i list 31 different ones.
Dawkins: The Greatest Show On Earth (2009, p. 409): Any mutation in the genetic code itself (as opposed to mutations in the genes that it encodes) would have an instantly catastrophic effect, not just in one place but throughout the whole organism. If any word in the 64-word dictionary changed its meaning, so that it came to specify a different amino acid, just about every protein in the body would instantaneously change, probably in many places along its length. Unlike an ordinary mutation…this would spell disaster. (2009, p. 409-10)
https://www.amazon.com/Greatest-Show-Earth-Evidence-Evolution/dp/1416594795
Dr. Jay L. Wile (2016):However, the eukaryotic cells that eventually evolved into vertebrates must have formed when a cell that used the “universal” code engulfed a cell that used yet another different code. As a result, invertebrates must have evolved from one line of eukaryotic cells, while vertebrates must have evolved from a completely separate line of eukaryotic cells. But this isn’t possible, since evolution depends on vertebrates evolving from invertebrates. Now, of course, this serious problem can be solved by assuming that while invertebrates evolved into vertebrates, their mitochondria also evolved to use a different genetic code. However, I am not really sure how that would be possible. After all, the invertebrates spent millions of years evolving, and through all those years, their mitochondrial DNA was set up based on one code. How could the code change without destroying the function of the mitochondria? At minimum, this adds another task to the long, long list of unfinished tasks necessary to explain how evolution could possibly work. Along with explaining how nuclear DNA can evolve to produce the new structures needed to change invertebrates into vertebrates, proponents of evolution must also explain how, at the same time, mitochondria can evolve to use a different genetic code! In the end, it seems to me that this wide variation in the genetic code deals a serious blow to the entire hypothesis of common ancestry, at least the way it is currently constructed. Perhaps that’s why I hadn’t heard about it until reading Dr. Rossiter’s excellent book.
http://blog.drwile.com/?p=14280
Bye-bye common ancestry !!
The basic process by which proteins are made in a cell. (click for credit)
I am still reading Shadow of Oz by Dr. Wayne Rossiter, and I definitely plan to post a review of it when I am finished. However, I wanted to write a separate blog post about one point that he makes in Chapter 6, which is entitled “Biological Evolution.” [url=https://books.google.com/books?id=kuwmCwAAQBAJ&pg=PT108&lpg=PT108&dq="To+date,+the+National+Center+for+Biotechnology+Information+%28NCBI%29,+which+houses+all+published+DNA+sequences"&source=bl&ots=y3djhymXWq&sig=SSjcioRSaQEZcuSGiztSRGYrJIw&hl=en&sa=X&ved=0ahUKEwjelt-frrPKAhWISCYKHSuJD9UQ6AEIHjAA#v=onepage&q="To date%2C the National Center for Biotechnology Information %28NCBI%29%2C which houses all published DNA]He says[/url]:
To date, the National Center for Biotechnology Information (NCBI), which houses all published DNA sequences (as well as RNA and protein sequences), currently acknowledges nineteen different coding languages for DNA…
He then references this page from the NCBI website.
This was a shock to me. As an impressionable young student at the University of Rochester, I was taught quite definitively that there is only one code for DNA, and it is universal. This, of course, is often cited as evidence for evolution. Consider, for example, this statement from The Biology Encyclopedia:
For almost all organisms tested, including humans, flies, yeast, and bacteria, the same codons are used to code for the same amino acids. Therefore, the genetic code is said to be universal. The universality of the genetic code strongly implies a common evolutionary origin to all organisms, even those in which the small differences have evolved. These include a few bacteria and protozoa that have a few variations, usually involving stop codons.
Dr. Rossiter points out that this isn’t anywhere close to correct, and it presents serious problems for the idea that all life descended from a single, common ancestor.
To understand the importance of Dr. Rossiter’s point, you need to know how a cell makes proteins. The basic steps of the process are illustrated in the image at the top of this post. The “recipe” for each protein is stored in DNA, and it is coded by four different nucleotide bases (abbreviated A, T, G, and C). That “recipe” is copied to a different molecule, RNA, in a process called transcription. During that process, the nucleotide base “U” is used instead of “T,” so the copy has A, U, G, and C as its four nucleotide bases. The copy then goes to the place where the proteins are actually made, which is called the ribosome. The ribosome reads the recipe in units called codons. Each codon, which consists of three nucleotide bases, specifies a particular amino acid. When the amino acids are strung together in the order given by the codons, the proper protein is made. The genetic code tells the cell which codon specifies which amino acid. Look, for example, at the illustration at the top of the page. The first codon in the RNA “recipe” is AUG. According to the supposedly universal genetic code, those three nucleotide bases in that order are supposed to code for one specific amino acid:methionine (abbreviated as “Met” in the illustration). The next codon (CCG) is supposed to code for the amino acid proline (abbreviated as Pro). Each possible three-letter sequence (each possible codon) codes for a specific amino acid, and the collection of all those possible codons and what they code for is often called the genetic code.
Now, once again, according to The Biology Encyclopedia (and many, many other sources), the genetic code is nearly universal. Aside from a few minor exceptions, all organisms use the same genetic code, and that points strongly to the idea that all organisms evolved from a common ancestor. However, according to the NCBI, that isn’t even close to correct. There are all sorts of exceptions to this “universal” genetic code, and I would think that some of them result in serious problems for the hypothesis of evolution. Consider, for example, the vertebrate mitochondrial code and the invertebrate mitochondrial code. In case you didn’t know, many cells actually have two sources of DNA. The main source of DNA is in the cell’s nucleus, so it is called nuclear DNA. However, the kinds of cells that make up vertebrates (animals with backbones) and invertebrates (animals without backbones) also have DNA in their mitochondria, small structures that are responsible for making most of the energy the cell uses to survive. The DNA found in mitochondria is called mitochondrial DNA. Now, according to the hypothesis of evolution, the kinds of cells that make up vertebrates and invertebrates (called eukaryotic cells) were not the first to evolve. Instead, the kinds of cells found in bacteria (called prokaryotic cells) supposedly evolved first. Then, at a later time, one prokaryotic cell supposedly engulfed another, but the engulfed cell managed to survive. Over generations, these two cells somehow managed to start working together, and the engulfed cell became the mitochondrion for the cell that engulfed it. This is the hypothesis of endosymbiosis, and despite its many, many problems, it is the standard tale of how prokaryotic cells became eukaryotic cells. However, if the mitochondria in invertebrates use a different genetic code from the mitochondria in vertebrates, and both of those codes are different from the “universal” genetic code, what does that tell us? It means that the eukaryotic cells that eventually evolved into invertebrates must have formed when a cell that used the “universal” code engulfed a cell that used a different code. However, the eukaryotic cells that eventually evolved into vertebrates must have formed when a cell that used the “universal” code engulfed a cell that used yet another different code. As a result, invertebrates must have evolved from one line of eukaryotic cells, while vertebrates must have evolved from a completely separate line of eukaryotic cells. But this isn’t possible, since evolution depends on vertebrates evolving from invertebrates. Now, of course, this serious problem can be solved by assuming that while invertebrates evolved into vertebrates, their mitochondria also evolved to use a different genetic code. However, I am not really sure how that would be possible. After all, the invertebrates spent millions of years evolving, and through all those years, their mitochondrial DNA was set up based on one code. How could the code change without destroying the function of the mitochondria? At minimum, this adds another task to the long, long list of unfinished tasks necessary to explain how evolution could possibly work. Along with explaining how nuclear DNA can evolve to produce the new structures needed to change invertebrates into vertebrates, proponents of evolution must also explain how, at the same time, mitochondria can evolve to use a different genetic code!
In the end, it seems to me that this wide variation in the genetic code deals a serious blow to the entire hypothesis of common ancestry, at least the way it is currently constructed. Perhaps that’s why I hadn’t heard about it until reading Dr. Rossiter’s excellent book.
http://blog.drwile.com/?p=14280
There are variants of the standard genetic code. These variants are used for instance in the mitochondria of many species, and they consist in the modification of one or several codons of the standard genetic code.
https://www.ncbi.nlm.nih.gov/pmc/articles/PMC2909233/
Richard Dawkins has claimed that the genetic code is universal across all organisms on earth. This is “near-conclusive proof,” he writes, that every living thing on this planet “descended from a single common ancestor” (1986, p. 270) at the root of Darwin’s universal tree of life. More recently, Dawkins repeated the claim in his bestseller The Greatest Show On Earth (2009, p. 409):
…the genetic code is universal, all but identical across animals, plants, fungi, bacteria, archaea and viruses. The 64-word dictionary, by which three letter DNA words are translated into 20 amino acids and one punctuation mark, which means ‘start reading here’ or ‘stop reading here,’ is the same 64-word dictionary wherever you look in the living kingdoms (with one or two exceptions too minor to undermine the generalization).
Let’s look at the reason Dawkins gives for why the code must be universal:
The reason is interesting. Any mutation in the genetic code itself (as opposed to mutations in the genes that it encodes) would have an instantly catastrophic effect, not just in one place but throughout the whole organism. If any word in the 64-word dictionary changed its meaning, so that it came to specify a different amino acid, just about every protein in the body would instantaneously change, probably in many places along its length. Unlike an ordinary mutation…this would spell disaster. (2009, p. 409-10)
And now, see here:
https://www.ncbi.nlm.nih.gov/Taxonomy/taxonomyhome.html/index.cgi?chapter=cgencodes
- 1. The Standard Code
- 2. The Vertebrate Mitochondrial Code
- 3. The Yeast Mitochondrial Code
- 4. The Mold, Protozoan, and Coelenterate Mitochondrial Code and the Mycoplasma/Spiroplasma Code
- 5. The Invertebrate Mitochondrial Code
- 6. The Ciliate, Dasycladacean and Hexamita Nuclear Code
- 9. The Echinoderm and Flatworm Mitochondrial Code
- 10. The Euplotid Nuclear Code
- 11. The Bacterial, Archaeal and Plant Plastid Code
- 12. The Alternative Yeast Nuclear Code
- 13. The Ascidian Mitochondrial Code
- 14. The Alternative Flatworm Mitochondrial Code
- 16. Chlorophycean Mitochondrial Code
- 21. Trematode Mitochondrial Code
- 22. Scenedesmus obliquus Mitochondrial Code
- 23. Thraustochytrium Mitochondrial Code
- 24. Rhabdopleuridae Mitochondrial Code
- 25. Candidate Division SR1 and Gracilibacteria Code
- 26. Pachysolen tannophilus Nuclear Code
- 27. Karyorelict Nuclear Code
- 28. Condylostoma Nuclear Code
- 29. Mesodinium Nuclear Code
- 30. Peritrich Nuclear Code
- 31. Blastocrithidia Nuclear Code
- 33. Cephalodiscidae Mitochondrial UAA-Tyr Code
Simple counting question: does “one or two” equal 33? That’s the number of known variant genetic codes compiled by the National Center for Biotechnology Information (NCBI). By any measure, Dawkins is off by an order of magnitude.

In human cells, the codon UGA codes for “stop,” meaning the end of an open reading frame (i.e., section of DNA coding for a protein). When the ribosome, the molecular machine that constructs proteins, encounters UGA in the messenger RNA of a human cell, it ceases translation. Not so in Mycoplasma, where UGA codes for the amino acid tryptophan. On encountering UGA in an mRNA strand, the Mycoplasma ribosome would insert a tryptophan (in the protein the ribosome is assembling) and keep chugging right along with translation, through the following codons, until it met a Mycoplasma stop codon. Human and Mycoplasma cells do not read their DNA in the same way.
We must bear in mind that most non-canonical codes evolved independently from the others, and so may have evolved through different steps
My comment: It is evident why the authors make that claim. As Dawkins wrote: Any mutation in the genetic code itself (as opposed to mutations in the genes that it encodes) would have an instantly catastrophic effect, not just in one place but throughout the whole organism. If any word in the 64-word dictionary changed its meaning, so that it came to specify a different amino acid, just about every protein in the body would instantaneously change, probably in many places along its length. Unlike an ordinary mutation…this would spell disaster.
And Dr.Wile: Someone can assume that while invertebrates evolved into vertebrates, their mitochondria also evolved to use a different genetic code. However, I am not really sure how that would be possible. After all, the invertebrates spent millions of years evolving, and through all those years, their mitochondrial DNA was set up based on one code. How could the code change without destroying the function of the mitochondria? At minimum, this adds another task to the long, long list of unfinished tasks necessary to explain how evolution could possibly work.
Even in a genome that has only 30-50 proteins, each protein is very long and uses the same amino acid multiple times. It would have to be shown how it is possible for four codons to go completely out of use. Then, how they can get reassigned in order to go from the “universal” code to the vertebrate mitochondrial code. Also, how did this happened only at the base of the vertebrate tree?
Why alternative genetic codes?
One reason why there are alternative genetic codes is the reduction of the number of tRNA needed. Furthermore, one alternative genetic code (the 'Echinoderm and Flatworm Mitochondrial Code') that seems to be better at reducing mutation and translation loads, and particularly yields better translation load except for very small AT content (approx. 20% AT content or less).
Of course, science literature claims that there was an adaptive advantage and improvement of fitness of these alternative codes, but how the transition could have happened is an open question.
The implications are significant: If the origin of the universal genetic code is an enigma, imagine another 33 different ones, that had to emerge independently !!!! This is simply evidence that the best explanation is an intelligent designer which created and generated different codes for different life forms separately. And it means, that the tree of life is bunk.
Since 1985 molecular biologists have discovered 33 different genetic codes in various species. Many of these are significantly different from the standard code. For example, the standard code has three different mRNA stop codons: UGA, UAA, and UAG . (A “stop codon” tells the cell to stop building-the protein is complete.) However, some variant codes have only one stop codon, UGA. The other “universal” stop codons now code for the amino acid glutamine. It’s very hard to see how an organism could have survived a transformation from the standard code to this one. Changing to this new code would cause the cell to produce useless strings of extra amino acids when it should have stopped protein production.
https://uncommondescent.com/evolution/there-are-now-many-variants-of-the-universal-genetic-code/
The Mechanisms of Codon Reassignments in Mitochondrial Genetic Codes 17 April 2006
If a change in the translation system occurs in an organism such that a codon is reassigned, most of the occurrences of this codon will still be at places where the old amino acid was preferred. We would expect the changes causing the codon reassignment to be strongly disadvantageous and to be eliminated by selection.
My comment: A reassignment means, that the tRNA's amino acid binding site would have to change to reassign a different amino acid.
The structural basis of the genetic code: amino acid recognition by aminoacyl-tRNA synthetases 28 July 2020 3
One of the most profound open questions in biology is how the genetic code was established. The correct read-out of genetic information is a delicate interplay between the composition of the binding site, non-covalent interactions, error correction mechanisms, and steric effects.
A glimpse into nature's looking glass -- to find the genetic code is reassigned: Stop codon varies widely 4
We were surprised to find that an unprecedented number of bacteria in the wild possess these codon reassignments, from "stop" to amino-acid encoding "sense," up to 10 percent of the time in some environments," said Rubin.
Another observation the researchers made was that beyond bacteria, these reassignments were also happening in phage, viruses that attack bacterial cells. Phage infect bacteria, injecting their DNA into the cell and exploiting the translational machinery of the cell to create more of themselves, to the point when the bacterial cell explodes, releasing more progeny phage particles to spread to neighboring bacteria and run amok.
The genetic translation system provides objective physical evidence of the first irreducible organic system on earth, and from it, all other organic systems follow. Moreover, this system is not the product of Darwinian evolution. Instead, it is the source of evolution (i.e. the physical conditions that enable life’s capacity to change and adapt over time) and as the first instance of specification on earth, it marks the rise of the genome and the starting point of heredity.
It is possible for mutations to cause disappearance of the codon in its original positions and reappearance in positions where the new amino acid is preferred. Mutations throughout the genome are required for it to readjust to the change in the genetic code. The problem is therefore to understand how codon reassignments can become fixed in a population despite being apparently deleterious in the intermediate stage before the genome has time to readjust.
There Are Now Many Variants Of The “Universal” Genetic Code June 13, 2018
Since 1985 molecular biologists have discovered at least 18 different genetic codes in various species.13 Many of these are significantly different from the standard code.14 For example, the standard code has three different mRNA stop codons: UGA, UAA, and UAG . (A “stop codon” tells the cell to stop building-the protein is complete.) However, some variant codes have only one stop codon, UGA. The other “universal” stop codons now code for the amino acid glutamine. It’s very hard to see how an organism could have survived a transformation from the standard code to this one. Changing to this new code would cause the cell to produce useless strings of extra amino acids when it should have stopped protein production.
https://uncommondescent.com/evolution/there-are-now-many-variants-of-the-universal-genetic-code/
Different genetic codes are strong evidence that they were designed.
Craig Venter vs Richard Dawkins:
It’s instructive to watch a fascinating exchange between Dawkins and genome guru J. Craig Venter, which occurred during a science forum held at Arizona State University. The question for discussion at the forum was “What is life?” Most of the panelists agreed that all organisms on Earth represent a single kind of life — a sample of one — because all organisms have descended from a last universal common ancestor (LUCA). This “sample of one” problem is strong motivation, panelist and NASA scientist Chris McKay argued, for exploring Mars and other planets (or their moons) in our solar system, to try to find a second example of life, unrelated to Earth organisms.
Venter disagreed — in a remarkable way (start at the 9:00 minute mark). “I’m not so sanguine as some of my colleagues here,” he said, “that there’s only one life form on this planet. We have a lot of different types of metabolism, different organisms. I wouldn’t call you [Venter said, turning to physicist Paul Davies, on his right] the same life form as the one we have that lives in pH 12 base, that would dissolve your skin if we dropped you in it.”
“Well, I’ve got the same genetic code,” said Davies. “We’ll have a common ancestor.”
“You don’t have the same genetic code,” replied Venter. “In fact, the Mycoplasmas [a group of bacteria Venter and his team have used to engineer synthetic chromosomes] use a different genetic code that would not work in your cells. So there are a lot of variations on the theme…”
Here Davies, a bit alarmed, interrupts Venter: “But you’re not saying it [i.e., Mycoplasma] belongs to a different tree of life from me, are you?”
“The tree of life is an artifact of some early scientific studies that aren’t really holding up…So there is not a tree of life.”
Dawkins is Flabbergasted
Fast forward to 11:23, when moderator Roger Bingham turns the microphone over to Dawkins:
“I’m intrigued,” replies Dawkins, “at Craig saying that the tree of life is a fiction. I mean…the DNA code of all creatures that have ever been looked at is all but identical.”
WHOPPER. Venter just told the forum that Mycoplasma read their DNA using a different coding convention than other organisms (for “stop” and tryptophan). But Dawkins is undaunted:
“Surely that means,” he asks Venter, “that they’re all related? Doesn’t it?”
As nearly as we can tell from the video, Venter only smiles.

https://www.sciencedirect.com/science/article/pii/S0960982216309174
2. https://uncommondescent.com/evolution/there-are-now-many-variants-of-the-universal-genetic-code/
https://www.youtube.com/watch?v=xIHMnD2FDeY
1. https://sci-hub.st/https://www.sciencedirect.com/science/article/pii/S0960982216309174
2. https://www.sciencedirect.com/journal/biosystems/vol/164/suppl/C
3. https://www.nature.com/articles/s41598-020-69100-0
4. https://www.sciencedaily.com/releases/2014/05/140522141422.htm
5. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC1894752/
Last edited by Otangelo on Wed Oct 18, 2023 4:05 pm; edited 10 times in total