

On origin of genetic code and tRNA before translation
Common language talks about DNA as 'information' or 'a code'. For a very long time, scientists suspected that something—some kind of plan, specificity or driving force—resided within the sperm and/or egg, such that a snake developed from a snake egg and humans created human offspring. But it was only in the late 1940s and 1950s, when cyberneticists, physicists and mathematicians entered the field of molecular biology, that scientists came to interpret this 'something' as information. The physicist Erwin Schrödinger probably coined the term 'code' when he described living organisms in terms of their molecular and atomic structure, in his influential book What is Life (Schrödinger, 1944). The complete pattern of the future development of an organism and its function when mature, Schrödinger wrote, is contained in the chromosomes in the form of a 'code'. His writings had a strong influence on both Francis Crick and James Watson and their later discovery of the structure of DNA. “Schrödinger probably wasn't the first, but he was the first one I'd read to say that there must be a code of some kind that allowed molecules in cells to carry information,” Watson said in an interview with Scientific American (Watson, 2003). Indeed, Watson and Crick, in a paper on the implications of their DNA structure, picked up Schrödinger's metaphor when they wrote that “it therefore seems likely that the precise sequence of the bases is the code which carries the genetical information.” 4
Just five nucleobases, also termed the genetic alphabet, are known to dominate the composition of deoxyribonucleic acid (DNA) and ribonucleic acid (RNA)

The quest of the origin of the coded information stored in DNA is a unresolved problem .
Lee Strobel writes:
“The six feet of DNA coiled inside every one of our body's one hundred trillion cells contains a four-letter chemical alphabet that spells out precise assembly instructions for all the proteins from which our bodies are made … No hypothesis has come close to explaining how information got into biological matter by naturalistic means” (Strobel, p. 282).
However, not only must the specified complex arrangement of the nucleotides stored in DNA be explained, which are the information required to make proteins, but also the origin of the basepairs itself and why only four bases, aka letters were selected, that is, the narrow selection of restricted variety of organic molecules upon which life is based. That is, in the same manner as not only the origin of the poem written through a alphabet might have to be figured out, but the origin of the alphabet itself, that is in our case, why 4, and not more or less nucleobases, but also why these four types, that is, why not different nucleobases since there are miridas from which the code could be chosen from. But also, why the assignment at all, rather than none ? Why arised a code, rather than none ? That is not a trivial question, but a fundamental one, which hardly can find good explanations through naturalism, however if a mind is involved, it makes perfect sense, since we know of minds inventing various kinds of alphabets all the time, there are european, asian, russian , japanese, chinese etc. types of alphabets.
In the paper :
On the Origin of the Canonical Nucleobases: An Assessment of Selection Pressures across Chemical and Early Biological Evolution 5
The native bases of RNA and DNA are prominent examples of the narrow selection of organic molecules upon which life is based. How did nature “decide” upon these specific heterocycles? Evidence suggests that many types of heterocycles could have been present on the early Earth. It is therefore likely that the contemporary composition of nucleobases is a result of multiple selection pressures that operated during early chemical and biological evolution. The persistence of the fittest heterocycles in the prebiotic environment towards, for example, hydrolytic and photochemical assaults, may have given some nucleobases a selective advantage for incorporation into the first informational polymers.
The prebiotic formation of polymeric nucleic acids employing the native bases remains, however, a challenging problem to reconcile.
Hypotheses have proposed that the emerging RNA world may have included many types of nucleobases. This is supported by the extensive utilization of non-canonical nucleobases in extant RNA and the resemblance of many of the modified bases to heterocycles generated in simulated prebiotic chemistry experiments.
The prebiotic formation of polymeric nucleic acids employing the native bases remains, however, a challenging problem to reconcile. Hypotheses have proposed that the emerging RNA world may have included many types of nucleobases. This is supported by the extensive utilization of non-canonical nucleobases in extant RNA and the resemblance of many of the modified bases to heterocycles generated in simulated prebiotic chemistry experiments. Selection pressures in the RNA world could have therefore narrowed the composition of the nucleic acid bases. Two such selection pressures may have been related to genetic fidelity and duplex stability. Considering these possible selection criteria, the native bases along with other related heterocycles seem to exhibit a certain level of fitness. We end by discussing the strength of the N-glycosidic bond as a potential fitness parameter in the early DNA world, which may have played a part in the refinement of the alphabetic bases.
So basically, there is no reason why the four extant nucleobases are selected. Any other could be assigned. But then there could be 4, 6, 10 or eventually even more nucleobases. This remains a challenging problem for naturalism, not however for intelligent design, where the creator selected arbitrarly the four bases to create life.
Since when did a prebiotic environment establish " selection pressures ", and why and how should there have been a goal to reach genetic fidelity and duplex stability ? There is triple stranded DNA, and it has nice stability
The alphabetic composition is the product of a continual process of refinement that evolved to its current state.
There is no evolution prior DNA replication.....
Not only the native bases were likely present on the early Earth, but so were many others. One of the more enigmatic and difficult problems confronting the prebiotic chemistry community is identifying how the monomers of RNA, or pre-RNA, or even non-related polymeric components selectively formed and self-assembled out of the presumed random prebiotic mixtures. Focusing on just a narrow view of RNA precursors, the linking of a nucleo-base to a ribose sugar is one such pressure. There are multiple ways in which a nucleobase can be attached to ribose via an N-glycosidic bond, but only one is found in contemporary nucleic acids (via the N9 of purines and N1 of pyrimidines). Achieving regio- and stereochemical selectivity of glycosylation reactions under simulated prebiotic conditions has plagued the community ever since Orgel and others began working on this problem.
We have found that a short stretch (30mer or larger) of triple-stranded DNA structure formed at the terminus (or very near) of linear DNA molecules is unusually stable, withstanding heat treatment at as high as 95 degrees C. 6
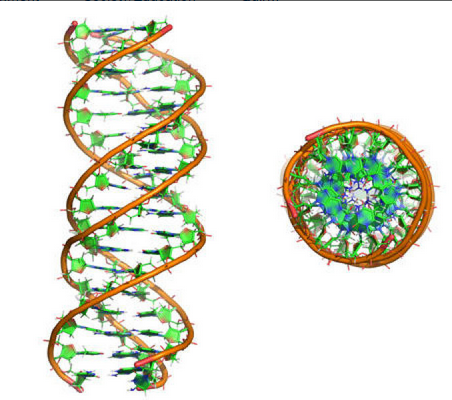
And the base pairs are also different :
The Hoogsteen base pair, consisting of a syn adenine base paired with an anti thymine base, is found in the 2.1 Å resolution structure of the MATα2 homeodomain bound to DNA in a region where a specifically and a non‐specifically bound homeodomain contact overlapping sites. 7
The paper then continues :
the alphabetic composition is the product of a continual process of refinement that evolved to its current state.
The only problem with this assertion is that they make things up. How do they know the state of affairs was due to evolution ? Answer : they don't know !! Atheists however will immediately conclude, because the paper says so, it must be true.......
Results from simulated prebiotic chemistry experiments conducted over the past fifty years and the ongoing analysis of meteorites provide evidence that not only the native bases were likely present on the early Earth, but so were many others.
So that means, life had many options, but choose to select just the extant four bases. See below
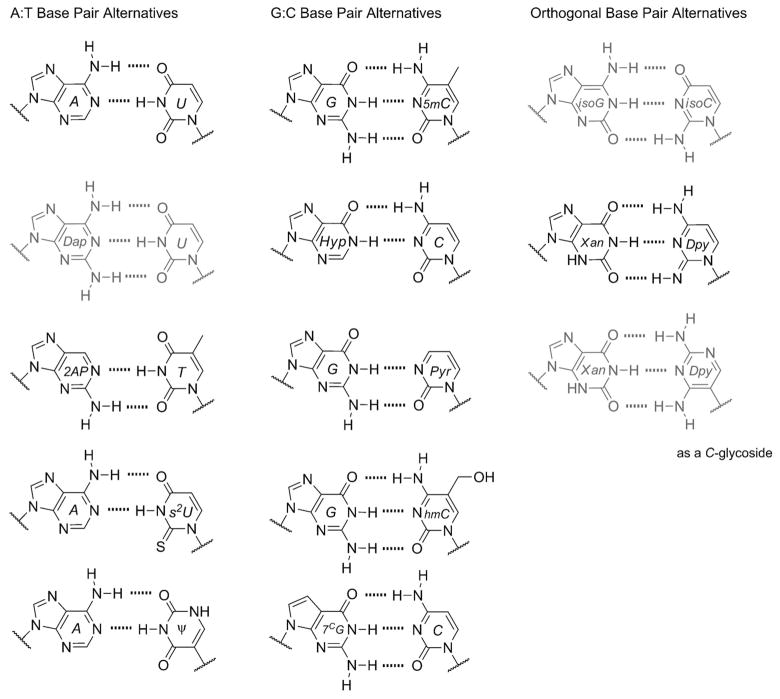
It would seem reasonable to hypothesize that the bases used by nature would have been selected to exhibit some of the highest stabilities against these spontaneous deamination reactions in comparison to alternative nucleobases.
Here applies the same as said above: Since when did a prebiotic environment establish " selection pressures ", and why and how should there have been a goal to reach highest stability against these spontaneous deamination reactions in comparison to alternative nucleobases ? It seems almost as if nature had the goal to create life ?
Greater persistence in this environment would have given the native bases an advantage over others, possibility facilitating their selective incorporation into the first primitive genetic polymers.
Again : nature has no mind, and no goals. And so it really does not matter at all, primitive genetic polymers are produced, or not.
1) http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3050877/
4) http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1298980/
5) http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4181368/
6) http://www.ncbi.nlm.nih.gov/pubmed/16769700
7) http://nar.oxfordjournals.org/content/30/23/5244
8 ) Bruce Alberts : Molecular biology of the cell , pg.367
9 ) file:///E:/Downloads/43-308-1-PB%20(1).pdf
http://www.ncbi.nlm.nih.gov/pubmed/3381099
Common language talks about DNA as 'information' or 'a code'. For a very long time, scientists suspected that something—some kind of plan, specificity or driving force—resided within the sperm and/or egg, such that a snake developed from a snake egg and humans created human offspring. But it was only in the late 1940s and 1950s, when cyberneticists, physicists and mathematicians entered the field of molecular biology, that scientists came to interpret this 'something' as information. The physicist Erwin Schrödinger probably coined the term 'code' when he described living organisms in terms of their molecular and atomic structure, in his influential book What is Life (Schrödinger, 1944). The complete pattern of the future development of an organism and its function when mature, Schrödinger wrote, is contained in the chromosomes in the form of a 'code'. His writings had a strong influence on both Francis Crick and James Watson and their later discovery of the structure of DNA. “Schrödinger probably wasn't the first, but he was the first one I'd read to say that there must be a code of some kind that allowed molecules in cells to carry information,” Watson said in an interview with Scientific American (Watson, 2003). Indeed, Watson and Crick, in a paper on the implications of their DNA structure, picked up Schrödinger's metaphor when they wrote that “it therefore seems likely that the precise sequence of the bases is the code which carries the genetical information.” 4
Just five nucleobases, also termed the genetic alphabet, are known to dominate the composition of deoxyribonucleic acid (DNA) and ribonucleic acid (RNA)
The quest of the origin of the coded information stored in DNA is a unresolved problem .
Lee Strobel writes:
“The six feet of DNA coiled inside every one of our body's one hundred trillion cells contains a four-letter chemical alphabet that spells out precise assembly instructions for all the proteins from which our bodies are made … No hypothesis has come close to explaining how information got into biological matter by naturalistic means” (Strobel, p. 282).
However, not only must the specified complex arrangement of the nucleotides stored in DNA be explained, which are the information required to make proteins, but also the origin of the basepairs itself and why only four bases, aka letters were selected, that is, the narrow selection of restricted variety of organic molecules upon which life is based. That is, in the same manner as not only the origin of the poem written through a alphabet might have to be figured out, but the origin of the alphabet itself, that is in our case, why 4, and not more or less nucleobases, but also why these four types, that is, why not different nucleobases since there are miridas from which the code could be chosen from. But also, why the assignment at all, rather than none ? Why arised a code, rather than none ? That is not a trivial question, but a fundamental one, which hardly can find good explanations through naturalism, however if a mind is involved, it makes perfect sense, since we know of minds inventing various kinds of alphabets all the time, there are european, asian, russian , japanese, chinese etc. types of alphabets.
In the paper :
On the Origin of the Canonical Nucleobases: An Assessment of Selection Pressures across Chemical and Early Biological Evolution 5
The native bases of RNA and DNA are prominent examples of the narrow selection of organic molecules upon which life is based. How did nature “decide” upon these specific heterocycles? Evidence suggests that many types of heterocycles could have been present on the early Earth. It is therefore likely that the contemporary composition of nucleobases is a result of multiple selection pressures that operated during early chemical and biological evolution. The persistence of the fittest heterocycles in the prebiotic environment towards, for example, hydrolytic and photochemical assaults, may have given some nucleobases a selective advantage for incorporation into the first informational polymers.
The prebiotic formation of polymeric nucleic acids employing the native bases remains, however, a challenging problem to reconcile.
Hypotheses have proposed that the emerging RNA world may have included many types of nucleobases. This is supported by the extensive utilization of non-canonical nucleobases in extant RNA and the resemblance of many of the modified bases to heterocycles generated in simulated prebiotic chemistry experiments.
The prebiotic formation of polymeric nucleic acids employing the native bases remains, however, a challenging problem to reconcile. Hypotheses have proposed that the emerging RNA world may have included many types of nucleobases. This is supported by the extensive utilization of non-canonical nucleobases in extant RNA and the resemblance of many of the modified bases to heterocycles generated in simulated prebiotic chemistry experiments. Selection pressures in the RNA world could have therefore narrowed the composition of the nucleic acid bases. Two such selection pressures may have been related to genetic fidelity and duplex stability. Considering these possible selection criteria, the native bases along with other related heterocycles seem to exhibit a certain level of fitness. We end by discussing the strength of the N-glycosidic bond as a potential fitness parameter in the early DNA world, which may have played a part in the refinement of the alphabetic bases.
So basically, there is no reason why the four extant nucleobases are selected. Any other could be assigned. But then there could be 4, 6, 10 or eventually even more nucleobases. This remains a challenging problem for naturalism, not however for intelligent design, where the creator selected arbitrarly the four bases to create life.
Since when did a prebiotic environment establish " selection pressures ", and why and how should there have been a goal to reach genetic fidelity and duplex stability ? There is triple stranded DNA, and it has nice stability
The alphabetic composition is the product of a continual process of refinement that evolved to its current state.
There is no evolution prior DNA replication.....
Not only the native bases were likely present on the early Earth, but so were many others. One of the more enigmatic and difficult problems confronting the prebiotic chemistry community is identifying how the monomers of RNA, or pre-RNA, or even non-related polymeric components selectively formed and self-assembled out of the presumed random prebiotic mixtures. Focusing on just a narrow view of RNA precursors, the linking of a nucleo-base to a ribose sugar is one such pressure. There are multiple ways in which a nucleobase can be attached to ribose via an N-glycosidic bond, but only one is found in contemporary nucleic acids (via the N9 of purines and N1 of pyrimidines). Achieving regio- and stereochemical selectivity of glycosylation reactions under simulated prebiotic conditions has plagued the community ever since Orgel and others began working on this problem.
We have found that a short stretch (30mer or larger) of triple-stranded DNA structure formed at the terminus (or very near) of linear DNA molecules is unusually stable, withstanding heat treatment at as high as 95 degrees C. 6
And the base pairs are also different :
The Hoogsteen base pair, consisting of a syn adenine base paired with an anti thymine base, is found in the 2.1 Å resolution structure of the MATα2 homeodomain bound to DNA in a region where a specifically and a non‐specifically bound homeodomain contact overlapping sites. 7
The paper then continues :
the alphabetic composition is the product of a continual process of refinement that evolved to its current state.
The only problem with this assertion is that they make things up. How do they know the state of affairs was due to evolution ? Answer : they don't know !! Atheists however will immediately conclude, because the paper says so, it must be true.......
Results from simulated prebiotic chemistry experiments conducted over the past fifty years and the ongoing analysis of meteorites provide evidence that not only the native bases were likely present on the early Earth, but so were many others.
So that means, life had many options, but choose to select just the extant four bases. See below
It would seem reasonable to hypothesize that the bases used by nature would have been selected to exhibit some of the highest stabilities against these spontaneous deamination reactions in comparison to alternative nucleobases.
Here applies the same as said above: Since when did a prebiotic environment establish " selection pressures ", and why and how should there have been a goal to reach highest stability against these spontaneous deamination reactions in comparison to alternative nucleobases ? It seems almost as if nature had the goal to create life ?
Greater persistence in this environment would have given the native bases an advantage over others, possibility facilitating their selective incorporation into the first primitive genetic polymers.
Again : nature has no mind, and no goals. And so it really does not matter at all, primitive genetic polymers are produced, or not.
1) http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3050877/
4) http://www.ncbi.nlm.nih.gov/pmc/articles/PMC1298980/
5) http://www.ncbi.nlm.nih.gov/pmc/articles/PMC4181368/
6) http://www.ncbi.nlm.nih.gov/pubmed/16769700
7) http://nar.oxfordjournals.org/content/30/23/5244
8 ) Bruce Alberts : Molecular biology of the cell , pg.367
9 ) file:///E:/Downloads/43-308-1-PB%20(1).pdf
http://www.ncbi.nlm.nih.gov/pubmed/3381099
Last edited by Admin on Thu Jan 21, 2016 2:12 pm; edited 3 times in total
