

The five levels of information in DNA
https://reasonandscience.catsboard.com/t1311-the-five-levels-of-information-in-dna
information, dividing it into five levels. Wherever information is found, it fits these five levels. These can be illustrated with a STOP sign.
The first level, statistics, tells us the STOP sign is one word and has four letters.
The second level, syntax, requires the information to fall within the rules of grammar such as correct spelling, word and sentence usage. The word STOP is spelled correctly.
The third level, semantics, provides meaning and implications. The STOP sign means that when we walk or drive and approach the sign we are to stop moving, look for traffic and proceed when it is safe.
The fourth level, pragmatics, is the application of the coded message. It is not enough to simply recognize the word STOP and understand what it means; we must actually stop when we approach the sign.
The fifth level, apobetics, is the overall purpose of the message. The STOP signs are placed by our local government to provide safety and traffic control.
The code in DNA completely conforms to all five of these levels of information.
Perry Marshall, Evolution 2.0 :
The alphabet (symbols), syntax (grammar), and semantics (meaning) of any communication system must be determined in advance, before any communication can take place. Otherwise, you could never be certain that what the transmitter is saying is the same as what the receiver is hearing. It’s like when you visit a Russian website and your browser doesn’t have the language plug-in for Russian. The text just appears as a bunch of squares. You would never have any idea if the Russian words were spelled right. When a message’s meaning is not yet decided, it requires intentional action by conscious agents to reach a consensus. The simple process of creating a new word in English, like blog (which was originally web log), requires speakers who agree on the meaning of the other words in their sentences. Then they have to mutually agree to define the new word in a specific way. Once a word is agreed upon, it is added to the dictionary. The dictionary is a decode table for the English language. Even if noise might occasionally give you a real word by accident, it could never also tell you what that word means. Every word has to be defined by mutual agreement and used in correct context in order to have meaning.
ANNALS OF THE NEW YORK ACADEMY OF SCIENCES, in the Issue: "The Year in Evolutionary Biology" page 62.
Conclusions
Information is the central currency for organismal fitness,and appears to be that which increases when organisms adapt to their niche. Information about the niche is stored in genes, and used to make predictions about the future states of the environment."
Information can be stored chemically as in DNA. The DNA molecule contains the Information for Life, but the molecule is not the Information. The Information defines Life. The DNA molecule is just the storage and transmission system for Information. The method of transmission and storage is not the Information itself.
All Information comes from a mind. When you read a book that someone wrote, you get a glimpse into the mind of the author. But the book is not the author. Neither is all of the author's mind in the book. And since a mind is non-physical, that means Information is spirit.
In the beginning (Time) was the Word (Information). And the Word was with God (Spirit) and the Word was God. He was in the beginning with God. All things (Space, Matter & Energy) were made through Him, and without Him, nothing was made that was made. In Him was (Life), and the Life was the (Light) of men. And the Light shines in the darkness, and the darkness did not comprehend it.
Experts in Information Theory define 5 LEVELS of Information: Statistics, Syntax, Semantics, Pragmatics, Apobetics 13
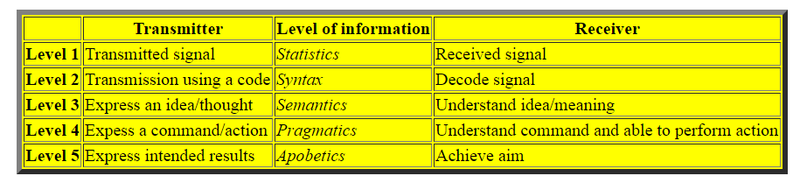
information, dividing it into five levels. Wherever information is found, it fits these five levels. These can be illustrated with a STOP sign.
The first level, statistics, tells us the STOP sign is one word and has four letters.
The second level, syntax, requires the information to fall within the rules of grammar such as correct spelling, word and sentence usage. The word STOP is spelled correctly.
The third level, semantics, provides meaning and implications. The STOP sign means that when we walk or drive and approach the sign we are to stop moving, look for traffic and proceed when it is safe.
The fourth level, pragmatics, is the application of the coded message. It is not enough to simply recognize the word STOP and understand what it means; we must actually stop when we approach the sign.
The fifth level, apobetics, is the overall purpose of the message. The STOP signs are placed by our local government to provide safety and traffic control.
The code in DNA completely conforms to all five of these levels of information.
Perry Marshall, Evolution 2.0 :
The alphabet (symbols), syntax (grammar), and semantics (meaning) of any communication system must be determined in advance, before any communication can take place. Otherwise, you could never be certain that what the transmitter is saying is the same as what the receiver is hearing. It’s like when you visit a Russian website and your browser doesn’t have the language plug-in for Russian. The text just appears as a bunch of squares. You would never have any idea if the Russian words were spelled right. When a message’s meaning is not yet decided, it requires intentional action by conscious agents to reach a consensus. The simple process of creating a new word in English, like blog (which was originally web log), requires speakers who agree on the meaning of the other words in their sentences. Then they have to mutually agree to define the new word in a specific way. Once a word is agreed upon, it is added to the dictionary. The dictionary is a decode table for the English language. Even if noise might occasionally give you a real word by accident, it could never also tell you what that word means. Every word has to be defined by mutual agreement and used in correct context in order to have meaning.
Statistics
In considering a book, a computer program or the genome of a human being we can ask the following questions: How many letters, numbers and words does the entire text consist of? How many individual letters of the alphabet (e.g. a, b, c … z for the Roman alphabet, or G, C, A and T for the DNA alphabet) are utilized? What is the frequency of occurrence of certain letters and words? To answer such questions it is irrelevant whether the text contains anything meaningful, is pure nonsense, or just randomly ordered sequences of symbols or words. Such investigations do not concern themselves with the content; they involve purely statistical aspects. All of this belongs to the first and thus bottom level of information: the level of statistics. The statistics level can be seen as the bridge between the material and the non-material world. (This is the level on which Claude E. Shannon developed his well-known mathematical concept of information.
Syntax
If we look at a text in any particular language, we see that only certain combinations of letters form permissible words of that particular language. This is determined by a pre-existing, wilful, convention. All other conceivable combinations do not belong to that language’s vocabulary. Syntax encompasses all of the structural characteristics of the way information is represented. This second level involves only the symbol system itself (the code) and the rules by which symbols and chains of symbols are combined (grammar, vocabulary). This is independent of any particular interpretation of the code.
To this end, they compared the rules of syntax (the way in which words are put together to form phrases and sentences), semantics (the study of meaning in language forms) and the basic rules of grammar. They found that the alkalines of our DNA follow a regular grammar and do have set rules just like our languages. So human languages did not appear coincidentally but are a reflection of our inherent DNA. 2
The 'grammar' of the human genetic code is more complex than that of even the most intricately constructed spoken languages in the world. The findings explain why the human genome is so difficult to decipher -- and contribute to the further understanding of how genetic differences affect the risk of developing diseases on an individual level. A new study from Sweden's Karolinska Institutet shows that the 'grammar' of the human genetic code is more complex than that of even the most intricately constructed spoken languages in the world. The findings, published in the journal Nature, explain why the human genome is so difficult to decipher -- and contribute to the further understanding of how genetic differences affect the risk of developing diseases on an individual level. knowing just the order of the letters is not sufficient for translating the genomic discoveries into medical benefits; one also needs to understand what the sequences of letters mean. In other words, it is necessary to identify the 'words' and the 'grammar' of the language of the genome. Their analysis reveals that the grammar of the genetic code is much more complex than that of even the most complex human languages. Instead of simply joining two words together by deleting a space, the individual words that are joined together in compound DNA words are altered, leading to a large number of completely new words.
Complex grammar of the genomic language
https://phys.org/news/2015-11-complex-grammar-genomic-language.html
Is DNA a pattern? Or is it a language?
DNA is an encoding and decoding system. DNA molecule represents more than itself; it represents an entire living organism. It doesn't just represent Adenine. It represents you or it represents a rabbit or a squirrel or a snake.
It has alphabet and syntax and semantics and pragmatics, or to use less technical terms alphabet, grammar, meaning and intent. 3
The linear arrangement of binding sites (sometimes called “grammar” or “syntax”) can play an important role in controlling enhancer output, especially by setting thresholds for gene activation. 4
The syntax structure of DNA follows Francis Crick’s central dogma of molecular biology “DNA-RNA-anything else”. But is this view coherent with recent empirical knowledge? Are cellular organisms only robot-like computing machines that function strictly according to their algorithm-based programming? Or, rather, are they coordinated complex entities that share bio-communication properties that may vary according to different context-specific needs? Is DNA the unequivocal syntax for sequences out of which one can construct living cells, viruses and phages for a household appliance? Or is the superficial molecular syntax of DNA solely the result of evolution’s long inserts and deletions of an abundance of various genetic parasites that shape host genomes? The most crucial questions are: do DNA sequences contain a hidden deep grammar structure that varies according to the meaning and context of environmental insults; do DNA sequences match with high fidelity environmental circumstances that led to epigenetic markings and memory? If yes, this would then mean that the identical DNA sequence may have various-even contradictory-meanings. In fact, this scenario is emerging as true[4-8]. 5
Only discovered in 1983, the Homeobox genes are a very exciting area of research right now. It is interesting to note that like a Makefile, 'HOX' genes only trigger things in other genes and don't materially build things themselves.
The homeobox 'syntax' appears to be very 'holy' in the sense described above. What happens if you copy paste the 'legs selector' part of a mouse HOX gene into the fruitfly Homeobox:
'In fact, when the mouse Hox-B6 gene is inserted in Drosophila, it can substitute for Antennapedia and produce legs in place of antennae' 6
our DNA stores data like a computer’s memory system. Not only that, but our genetic code uses grammar rules and syntax in a way that closely mirrors human language! 7
Semantics
Sequences of symbols and syntactic rules form the necessary pre-conditions for the representation of information. But the critical issue concerning information transmission is not the particular code chosen, nor the size, number or form of the letters—nor even the method of transmission. It is, rather, the semantics (Greek: semantikós = significant meaning), i.e. the message it contains—the proposition, the sense, the meaning.
Information itself is never the actual object or act, neither is it a relationship (event or idea), but encoded symbols merely represent that which is discussed. Symbols of extremely different nature play a substitutionary role with regard to the reality or a system of thought. Information is always an abstract representation of something quite different. For example, the symbols in today’s newspaper represent an event that happened yesterday; this event is not contemporaneous; moreover, it might have happened in another country and is not at all present where and when the information is transmitted. The genetic words in a DNA molecule represent the specific amino acids that will be used at a later stage for synthesis of protein molecules.
'DNA' has acquired semantic power. Quite what it means is not so clear, but its significance is all: it is the secret of life, the blueprint, the instruction manual. 9
The nominables in the set of DNA string represent “signs”, whereas those in the set of proteins (results of decoding the information) represent the “meaning” of those bits and pieces of information. 11
Any code is based on meaning and a genetic code does exist in every cell. The third paradigm, in short, is the view that organic information and organic meaning exist in every living system because they are the inevitable results of the processes of copying and coding that produce genes and proteins. According to this view, life is ‘chemistry-plus-information-plus-codes’. 12
The true nature of organic information and organic meaning has for a long time eluded us because they exist only in artefacts and biologists have not yet come to terms with the idea that life is artefact making. This is the idea that life arose from matter and yet it is fundamentally different from it because inanimate matter is made of spontaneously formed objects whereas life is made of objects that are manufactured by molecular machines.
Pragmatics
Information invites action. In this context it is irrelevant whether the receiver of information acts in the manner desired by the sender of the information, or reacts in the opposite way, or doesn’t do anything at all. Every transmission of information is nevertheless associated with the expectation, from the side of the sender, of generating a particular result or effect on the receiver. Even the shortest advertising slogan for a washing powder is intended to result in the receiver carrying out the action of purchasing this particular brand in preference to others. We have thus reached a completely new level at which information operates, which we call pragmatics (Greek pragma = action, doing). The sender is also involved in action to further his desired outcome (more sales/profit), e.g. designing the best message (semantics) and transmitting it as widely as possible in newspapers, TV, etc.
Apobetics
We have already recognized that for any given information the sender is pursuing a goal. We have now reached the last and highest level at which information operates: namely, apobetics (the aspect of information concerned with the goal, the result itself). In linguistic analogy to the previous descriptions the author has here introduced the term “apobetics” (from the Greek apobeinon = result, consequence). The outcome on the receiver’s side is predicated upon the goal demanded/desired by the sender—that is, the plan or conception. The apobetics aspect of information is the most important of the five levels because it concerns the question of the outcome intended by the sender.
The disciplineof embryology would be incomprehensible without apobetics. 8 For example, the large, bony plates on the back of the stegosaur are of no practical use to the embryo, yet the stegosaur embryo develops these plate structures. The reason it does so is for the benefit of the adult (it is currently supposed that the adult used them for temperature control). The end (the benefit to the adult) determines the means (the development in the embryo). Non-biological causality usually proceeds the other way around—the cause precedes the effect. But in biology, the effect (embryonic development) precedes the cause (the needs of the adult organism). This inverse causality is the essence of apobetics
http://chemistry.umeche.maine.edu/CHY431/Code.html
The primary purpose of DNA is information storage.
Applying Shannon's information theory to bacterial and phage genomes and metagenomes
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3539204/
Among the mathematical methods used, Shannon's uncertainty has previously been considered as a genome analysis strategy. In the work of Chang and colleagues, Shannon's uncertainty was calculated for complete prokaryotic and eukaryotic genomes available at that time, and it was found that genomes belonged to a universality class that could be mathematically represented by a simple formula, yet Plasmodium genomes stood out as an intriguing exception, still unexplained. Additionally, the variation of Shannon's index with sequence word length and genome length was examined. Here, our findings confirmed and advanced that study by establishing the relationship between word size and genome length for calculating Shannon's index.
We also found that at a certain word lengths, Shannon's index can be used to differentiate phage and bacterial sequences. Although this differentiation is sensitive to genome length, with some modification, this observation can help find phage genes embedded in bacterial genomes. As an application, we calculated Shannon's index for a group of DNA sequences using a word size of nt (four consecutive amino acids) and we were able to use this group of sequences to detect prophages in bacterial genomes.
http://evidencepress.com/articles/evidence-for-the-existence-of-god/
http://creation.com/lipid-rafts-evidence-of-biosyntax-and-biopragmatics
the nucleotide sequence found in DNA represents statistical information, the amino acids specified by codons represent a semantic arrangement, the sequence of amino acids represents a syntactic arrangement, and the function of gene products represents a pragmatic arrangement. This description is appropriate but is incomplete because gene products do not simply operate pragmatically but also form syntactic, semantic and pragmatic arrangements within ever more complex processes that make up the whole living organism.
1. https://answersingenesis.org/genetics/information-theory/the-five-levels-of-the-information-concept/
2. http://wakeup-world.com/2011/07/12/scientist-prove-dna-can-be-reprogrammed-by-words-frequencies/
3. http://www.ukapologetics.net/10/DNA.htm
4. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4988584/
5. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4160521/
6. https://ds9a.nl/amazing-dna/
7. http://undergroundhealthreporter.com/dna-science-and-reprograming-your-dna/
8. http://creation.com/images/pdfs/tj/j19_2/j19_2_29-35.pdf
9. http://www.nature.com/ng/journal/v33/n4/full/ng0403-453.html
10. https://www.sciencedaily.com/releases/2015/11/151109140252.htm
11. https://web.natur.cuni.cz/filosof/markos/Publikace/AMFC_biosemio12.pdf
12. Marcello Barbieri, Code Biology A New Science of Life, page 19
13. http://www.ichthus.info/Evolution/information.html
Further readings:
http://www.answersingenesis.org/articles/tj/v10/n2/information-science-biology
http://www.answersingenesis.org/articles/itbwi/five-levels-information-concept
http://creation.com/laws-of-information
https://reasonandscience.catsboard.com/t1311-the-five-levels-of-information-in-dna
information, dividing it into five levels. Wherever information is found, it fits these five levels. These can be illustrated with a STOP sign.
The first level, statistics, tells us the STOP sign is one word and has four letters.
The second level, syntax, requires the information to fall within the rules of grammar such as correct spelling, word and sentence usage. The word STOP is spelled correctly.
The third level, semantics, provides meaning and implications. The STOP sign means that when we walk or drive and approach the sign we are to stop moving, look for traffic and proceed when it is safe.
The fourth level, pragmatics, is the application of the coded message. It is not enough to simply recognize the word STOP and understand what it means; we must actually stop when we approach the sign.
The fifth level, apobetics, is the overall purpose of the message. The STOP signs are placed by our local government to provide safety and traffic control.
The code in DNA completely conforms to all five of these levels of information.
Perry Marshall, Evolution 2.0 :
The alphabet (symbols), syntax (grammar), and semantics (meaning) of any communication system must be determined in advance, before any communication can take place. Otherwise, you could never be certain that what the transmitter is saying is the same as what the receiver is hearing. It’s like when you visit a Russian website and your browser doesn’t have the language plug-in for Russian. The text just appears as a bunch of squares. You would never have any idea if the Russian words were spelled right. When a message’s meaning is not yet decided, it requires intentional action by conscious agents to reach a consensus. The simple process of creating a new word in English, like blog (which was originally web log), requires speakers who agree on the meaning of the other words in their sentences. Then they have to mutually agree to define the new word in a specific way. Once a word is agreed upon, it is added to the dictionary. The dictionary is a decode table for the English language. Even if noise might occasionally give you a real word by accident, it could never also tell you what that word means. Every word has to be defined by mutual agreement and used in correct context in order to have meaning.
ANNALS OF THE NEW YORK ACADEMY OF SCIENCES, in the Issue: "The Year in Evolutionary Biology" page 62.
Conclusions
Information is the central currency for organismal fitness,and appears to be that which increases when organisms adapt to their niche. Information about the niche is stored in genes, and used to make predictions about the future states of the environment."
Information can be stored chemically as in DNA. The DNA molecule contains the Information for Life, but the molecule is not the Information. The Information defines Life. The DNA molecule is just the storage and transmission system for Information. The method of transmission and storage is not the Information itself.
All Information comes from a mind. When you read a book that someone wrote, you get a glimpse into the mind of the author. But the book is not the author. Neither is all of the author's mind in the book. And since a mind is non-physical, that means Information is spirit.
In the beginning (Time) was the Word (Information). And the Word was with God (Spirit) and the Word was God. He was in the beginning with God. All things (Space, Matter & Energy) were made through Him, and without Him, nothing was made that was made. In Him was (Life), and the Life was the (Light) of men. And the Light shines in the darkness, and the darkness did not comprehend it.
Experts in Information Theory define 5 LEVELS of Information: Statistics, Syntax, Semantics, Pragmatics, Apobetics 13


information, dividing it into five levels. Wherever information is found, it fits these five levels. These can be illustrated with a STOP sign.
The first level, statistics, tells us the STOP sign is one word and has four letters.
The second level, syntax, requires the information to fall within the rules of grammar such as correct spelling, word and sentence usage. The word STOP is spelled correctly.
The third level, semantics, provides meaning and implications. The STOP sign means that when we walk or drive and approach the sign we are to stop moving, look for traffic and proceed when it is safe.
The fourth level, pragmatics, is the application of the coded message. It is not enough to simply recognize the word STOP and understand what it means; we must actually stop when we approach the sign.
The fifth level, apobetics, is the overall purpose of the message. The STOP signs are placed by our local government to provide safety and traffic control.
The code in DNA completely conforms to all five of these levels of information.
Perry Marshall, Evolution 2.0 :
The alphabet (symbols), syntax (grammar), and semantics (meaning) of any communication system must be determined in advance, before any communication can take place. Otherwise, you could never be certain that what the transmitter is saying is the same as what the receiver is hearing. It’s like when you visit a Russian website and your browser doesn’t have the language plug-in for Russian. The text just appears as a bunch of squares. You would never have any idea if the Russian words were spelled right. When a message’s meaning is not yet decided, it requires intentional action by conscious agents to reach a consensus. The simple process of creating a new word in English, like blog (which was originally web log), requires speakers who agree on the meaning of the other words in their sentences. Then they have to mutually agree to define the new word in a specific way. Once a word is agreed upon, it is added to the dictionary. The dictionary is a decode table for the English language. Even if noise might occasionally give you a real word by accident, it could never also tell you what that word means. Every word has to be defined by mutual agreement and used in correct context in order to have meaning.
Statistics
In considering a book, a computer program or the genome of a human being we can ask the following questions: How many letters, numbers and words does the entire text consist of? How many individual letters of the alphabet (e.g. a, b, c … z for the Roman alphabet, or G, C, A and T for the DNA alphabet) are utilized? What is the frequency of occurrence of certain letters and words? To answer such questions it is irrelevant whether the text contains anything meaningful, is pure nonsense, or just randomly ordered sequences of symbols or words. Such investigations do not concern themselves with the content; they involve purely statistical aspects. All of this belongs to the first and thus bottom level of information: the level of statistics. The statistics level can be seen as the bridge between the material and the non-material world. (This is the level on which Claude E. Shannon developed his well-known mathematical concept of information.
Syntax
If we look at a text in any particular language, we see that only certain combinations of letters form permissible words of that particular language. This is determined by a pre-existing, wilful, convention. All other conceivable combinations do not belong to that language’s vocabulary. Syntax encompasses all of the structural characteristics of the way information is represented. This second level involves only the symbol system itself (the code) and the rules by which symbols and chains of symbols are combined (grammar, vocabulary). This is independent of any particular interpretation of the code.
To this end, they compared the rules of syntax (the way in which words are put together to form phrases and sentences), semantics (the study of meaning in language forms) and the basic rules of grammar. They found that the alkalines of our DNA follow a regular grammar and do have set rules just like our languages. So human languages did not appear coincidentally but are a reflection of our inherent DNA. 2
The 'grammar' of the human genetic code is more complex than that of even the most intricately constructed spoken languages in the world. The findings explain why the human genome is so difficult to decipher -- and contribute to the further understanding of how genetic differences affect the risk of developing diseases on an individual level. A new study from Sweden's Karolinska Institutet shows that the 'grammar' of the human genetic code is more complex than that of even the most intricately constructed spoken languages in the world. The findings, published in the journal Nature, explain why the human genome is so difficult to decipher -- and contribute to the further understanding of how genetic differences affect the risk of developing diseases on an individual level. knowing just the order of the letters is not sufficient for translating the genomic discoveries into medical benefits; one also needs to understand what the sequences of letters mean. In other words, it is necessary to identify the 'words' and the 'grammar' of the language of the genome. Their analysis reveals that the grammar of the genetic code is much more complex than that of even the most complex human languages. Instead of simply joining two words together by deleting a space, the individual words that are joined together in compound DNA words are altered, leading to a large number of completely new words.
Complex grammar of the genomic language
https://phys.org/news/2015-11-complex-grammar-genomic-language.html
Is DNA a pattern? Or is it a language?
DNA is an encoding and decoding system. DNA molecule represents more than itself; it represents an entire living organism. It doesn't just represent Adenine. It represents you or it represents a rabbit or a squirrel or a snake.
It has alphabet and syntax and semantics and pragmatics, or to use less technical terms alphabet, grammar, meaning and intent. 3
The linear arrangement of binding sites (sometimes called “grammar” or “syntax”) can play an important role in controlling enhancer output, especially by setting thresholds for gene activation. 4
The syntax structure of DNA follows Francis Crick’s central dogma of molecular biology “DNA-RNA-anything else”. But is this view coherent with recent empirical knowledge? Are cellular organisms only robot-like computing machines that function strictly according to their algorithm-based programming? Or, rather, are they coordinated complex entities that share bio-communication properties that may vary according to different context-specific needs? Is DNA the unequivocal syntax for sequences out of which one can construct living cells, viruses and phages for a household appliance? Or is the superficial molecular syntax of DNA solely the result of evolution’s long inserts and deletions of an abundance of various genetic parasites that shape host genomes? The most crucial questions are: do DNA sequences contain a hidden deep grammar structure that varies according to the meaning and context of environmental insults; do DNA sequences match with high fidelity environmental circumstances that led to epigenetic markings and memory? If yes, this would then mean that the identical DNA sequence may have various-even contradictory-meanings. In fact, this scenario is emerging as true[4-8]. 5
Only discovered in 1983, the Homeobox genes are a very exciting area of research right now. It is interesting to note that like a Makefile, 'HOX' genes only trigger things in other genes and don't materially build things themselves.
The homeobox 'syntax' appears to be very 'holy' in the sense described above. What happens if you copy paste the 'legs selector' part of a mouse HOX gene into the fruitfly Homeobox:
'In fact, when the mouse Hox-B6 gene is inserted in Drosophila, it can substitute for Antennapedia and produce legs in place of antennae' 6
our DNA stores data like a computer’s memory system. Not only that, but our genetic code uses grammar rules and syntax in a way that closely mirrors human language! 7
Semantics
Sequences of symbols and syntactic rules form the necessary pre-conditions for the representation of information. But the critical issue concerning information transmission is not the particular code chosen, nor the size, number or form of the letters—nor even the method of transmission. It is, rather, the semantics (Greek: semantikós = significant meaning), i.e. the message it contains—the proposition, the sense, the meaning.
Information itself is never the actual object or act, neither is it a relationship (event or idea), but encoded symbols merely represent that which is discussed. Symbols of extremely different nature play a substitutionary role with regard to the reality or a system of thought. Information is always an abstract representation of something quite different. For example, the symbols in today’s newspaper represent an event that happened yesterday; this event is not contemporaneous; moreover, it might have happened in another country and is not at all present where and when the information is transmitted. The genetic words in a DNA molecule represent the specific amino acids that will be used at a later stage for synthesis of protein molecules.
'DNA' has acquired semantic power. Quite what it means is not so clear, but its significance is all: it is the secret of life, the blueprint, the instruction manual. 9
The nominables in the set of DNA string represent “signs”, whereas those in the set of proteins (results of decoding the information) represent the “meaning” of those bits and pieces of information. 11
Any code is based on meaning and a genetic code does exist in every cell. The third paradigm, in short, is the view that organic information and organic meaning exist in every living system because they are the inevitable results of the processes of copying and coding that produce genes and proteins. According to this view, life is ‘chemistry-plus-information-plus-codes’. 12
The true nature of organic information and organic meaning has for a long time eluded us because they exist only in artefacts and biologists have not yet come to terms with the idea that life is artefact making. This is the idea that life arose from matter and yet it is fundamentally different from it because inanimate matter is made of spontaneously formed objects whereas life is made of objects that are manufactured by molecular machines.
Pragmatics
Information invites action. In this context it is irrelevant whether the receiver of information acts in the manner desired by the sender of the information, or reacts in the opposite way, or doesn’t do anything at all. Every transmission of information is nevertheless associated with the expectation, from the side of the sender, of generating a particular result or effect on the receiver. Even the shortest advertising slogan for a washing powder is intended to result in the receiver carrying out the action of purchasing this particular brand in preference to others. We have thus reached a completely new level at which information operates, which we call pragmatics (Greek pragma = action, doing). The sender is also involved in action to further his desired outcome (more sales/profit), e.g. designing the best message (semantics) and transmitting it as widely as possible in newspapers, TV, etc.
Apobetics
We have already recognized that for any given information the sender is pursuing a goal. We have now reached the last and highest level at which information operates: namely, apobetics (the aspect of information concerned with the goal, the result itself). In linguistic analogy to the previous descriptions the author has here introduced the term “apobetics” (from the Greek apobeinon = result, consequence). The outcome on the receiver’s side is predicated upon the goal demanded/desired by the sender—that is, the plan or conception. The apobetics aspect of information is the most important of the five levels because it concerns the question of the outcome intended by the sender.
The disciplineof embryology would be incomprehensible without apobetics. 8 For example, the large, bony plates on the back of the stegosaur are of no practical use to the embryo, yet the stegosaur embryo develops these plate structures. The reason it does so is for the benefit of the adult (it is currently supposed that the adult used them for temperature control). The end (the benefit to the adult) determines the means (the development in the embryo). Non-biological causality usually proceeds the other way around—the cause precedes the effect. But in biology, the effect (embryonic development) precedes the cause (the needs of the adult organism). This inverse causality is the essence of apobetics
http://chemistry.umeche.maine.edu/CHY431/Code.html
The primary purpose of DNA is information storage.
Applying Shannon's information theory to bacterial and phage genomes and metagenomes
http://www.ncbi.nlm.nih.gov/pmc/articles/PMC3539204/
Among the mathematical methods used, Shannon's uncertainty has previously been considered as a genome analysis strategy. In the work of Chang and colleagues, Shannon's uncertainty was calculated for complete prokaryotic and eukaryotic genomes available at that time, and it was found that genomes belonged to a universality class that could be mathematically represented by a simple formula, yet Plasmodium genomes stood out as an intriguing exception, still unexplained. Additionally, the variation of Shannon's index with sequence word length and genome length was examined. Here, our findings confirmed and advanced that study by establishing the relationship between word size and genome length for calculating Shannon's index.
We also found that at a certain word lengths, Shannon's index can be used to differentiate phage and bacterial sequences. Although this differentiation is sensitive to genome length, with some modification, this observation can help find phage genes embedded in bacterial genomes. As an application, we calculated Shannon's index for a group of DNA sequences using a word size of nt (four consecutive amino acids) and we were able to use this group of sequences to detect prophages in bacterial genomes.
http://evidencepress.com/articles/evidence-for-the-existence-of-god/
http://creation.com/lipid-rafts-evidence-of-biosyntax-and-biopragmatics
the nucleotide sequence found in DNA represents statistical information, the amino acids specified by codons represent a semantic arrangement, the sequence of amino acids represents a syntactic arrangement, and the function of gene products represents a pragmatic arrangement. This description is appropriate but is incomplete because gene products do not simply operate pragmatically but also form syntactic, semantic and pragmatic arrangements within ever more complex processes that make up the whole living organism.
1. https://answersingenesis.org/genetics/information-theory/the-five-levels-of-the-information-concept/
2. http://wakeup-world.com/2011/07/12/scientist-prove-dna-can-be-reprogrammed-by-words-frequencies/
3. http://www.ukapologetics.net/10/DNA.htm
4. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4988584/
5. https://www.ncbi.nlm.nih.gov/pmc/articles/PMC4160521/
6. https://ds9a.nl/amazing-dna/
7. http://undergroundhealthreporter.com/dna-science-and-reprograming-your-dna/
8. http://creation.com/images/pdfs/tj/j19_2/j19_2_29-35.pdf
9. http://www.nature.com/ng/journal/v33/n4/full/ng0403-453.html
10. https://www.sciencedaily.com/releases/2015/11/151109140252.htm
11. https://web.natur.cuni.cz/filosof/markos/Publikace/AMFC_biosemio12.pdf
12. Marcello Barbieri, Code Biology A New Science of Life, page 19
13. http://www.ichthus.info/Evolution/information.html
Further readings:
http://www.answersingenesis.org/articles/tj/v10/n2/information-science-biology
http://www.answersingenesis.org/articles/itbwi/five-levels-information-concept
http://creation.com/laws-of-information
Last edited by Otangelo on Sat May 28, 2022 12:42 pm; edited 34 times in total