

Shannon’s Theory of Information 1
Most of the experts debating the origin of information rely on the mathematical model of communication developed by the late Claude Shannon with its quantitative merits.2–4 Shannon’s fame began with publication of his master’s thesis, which was called “possibly the most important, and also the most famous, master’s thesis of the century”.5
Messages are strings of symbols, like ‘10011101’, ‘ACCTGGTCAA’, and ‘go away’. All messages are composed of symbols taken from a coding alphabet. The English alphabet uses 26 symbols, the DNA code, four, and binary codes use two symbols.
Hubert Yockey is a pioneer in applying Shannon’s theory to biology. Once it was realized that the genetic code uses four nucleobases, abbreviated A, C, G, and T, in combinations of three to code for amino acids, the relevance of Information Theory became quickly apparent. Yockey used the mathematical formalism of Shannon’s work to evaluate the information of cytochrome c proteins, selected due to the large number of sequence examples available. Many proteins are several times larger, or show far less tolerance to variability, as is the case of another example Yockey discusses:
Yockey seems to believe the information was front-loaded on to DNA about four billion years ago in some primitive organism. This viewpoint is not elaborated on by him and is deduced primarily by his comments that Shannon’s Channel Capacity Theorem ensures transmission of the original message correctly.
Bio-physicist Lee Spetner, Ph.D. from MIT, is a leading information theoretician who wrote the book Not by Chance.27 He is a very lucid participant in Internet debates on evolution and information theory, and is adamant that evolutionary processes quantitatively won’t increase information. In his book, he wrote,
Within Shannon’s framework, it is correct that a random mutation could increase information content. However, one must not automatically conflate ‘more information content’ with good or useful. Although Spetner says information could be in principle created or increased, Dr Werner Gitt, retired Director and Professor at the German Federal Institute of Physics and Technology, denies this:
In his latest book, Gitt refines and explains his conclusions from a lifetime of research on information and its inseparable reliance on an intelligent source. There are various manifestations of information: for example, the spider’s web; the diffraction pattern of butterfly wings; development of embryos; and an organ-playing robot. He introduces the term ‘Universal Information’ to minimize confusion with other usages of the word information:
Information must be encoded on a series of symbols which satisfy three Necessary Conditions (NC). These are conclusions, based on observation.
Gitt also concludes that UI is embedded in a five-level hierarchy with each level building upon the lower one:
[1]statistics (signal, number of symbols)
[2]cosyntics (set of symbols, grammar)
[3]semantics (meaning)
[4]pragmatics (action)
[5]apobetics (purpose, result).
Gitt believes information is guided by immutable Scientific Laws of Information (SLIs).36,37 Unless shown to be wrong, they deny a naturalist origin for information, and they are:
These laws are inconsistent with the assumption stated by Nobel Prize winner and origin-of-life specialist Manfred Eigen: “The logic of life has its origin in physics and chemistry.” The issue of information, the basis of genetics and morphology, has simply been ignored. On the other hand,
Norbert Wiener, a leading pioneer in information theory, understood clearly that, “Information is information, neither matter nor energy. Any materialism that disregards this will not live to see another day.”
It is apparent that Gitt views Shannon’s model as inadequate to handle most aspects of information, and that he means something entirely different by the word ‘information’.
Arch-atheist Richard Dawkins reveals a Shannon orientation to what information means when he wrote, “Information, in the technical sense, is surprise value, measured as the inverse of expected probability.” He adds, “It is a theory which has long held a fascination for me, and I have used it in several of my research papers over the years.” And more specifically,
In articles and discussions among non-specialists, questions are raised such as “Where does the information come from to create wings?” There is an intuition among most of us that adding biological novelty requires information, and more features implies more information. I suspect this is what lies behind claims that evolutionary processes cannot create information, meaning complex new biological features. Even Dawkins subscribes to this intuitive notion of information:
Stephen C. Meyer, director of the Discovery Institute’s Center for Science and Culture and active member of the Intelligent Design movement, relies on Shannon’s theory for his critiques on naturalism. He recognizes that some sequences of characters serve a deliberate and useful purpose. Meyer says the messages with this property exhibit specified complexity, or specified information.Shannon’s Theory of Communication itself has no need to address the question of usefulness, value, or meaning of transmitted messages. In fact, he later avoided the word information. His concern was how to transmit messages error-free. But Meyer points out that
I believe Meyer’s definition of information corresponds to Durston’s Functional Information.
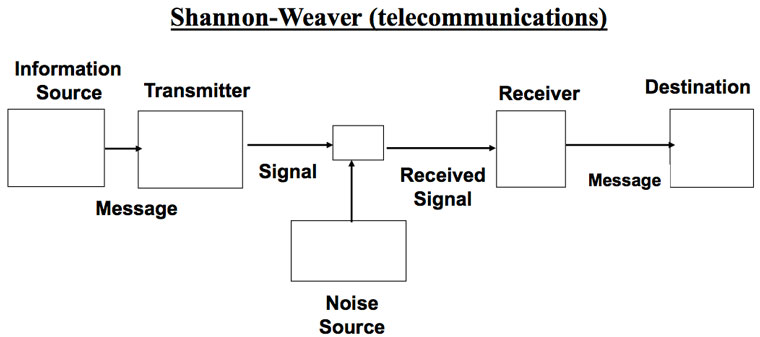
[size=10]Figure 1. Shannon’s schematic diagram of a general communication system.2[/size]
William Dembski, another prominent figure in the Intelligent Design movement, is a major leader in the analysis of the properties and calculations of information, and will be referred to in the next parts to this series. He has not reported any analysis of his own on protein or gene sequences, but also accepts that H0–Hf is the relevant measure from Shannon’s work to quantify information.
In part 2 of this series I’ll show that many things are implied in Shannon’s theory that indicate an underlying active intelligence.
Thomas Schneider is a Research Biologist at the National Institutes of Health. His Ph.D. thesis in 1984 was on applying Shannon’s Information Theory to DNA and RNA binding sites and he has continued this work ever since and published extensively.
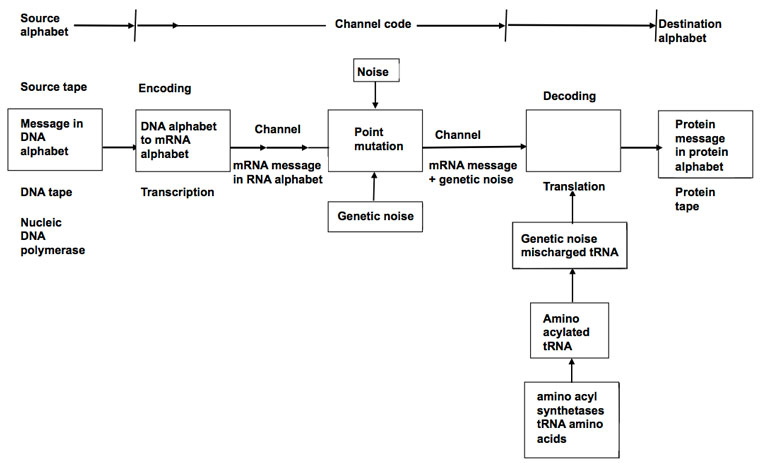
[size=10]Figure 2. The transmission of genetic message from the DNA tape to the protein tape, according to Yockey.17[/size]
There is common agreement that a sender initiates transmission of a coded message which is received and decoded by a receiver. Figure 1 shows how Shannon depicted this and figure 2 shows Yockey’s version.
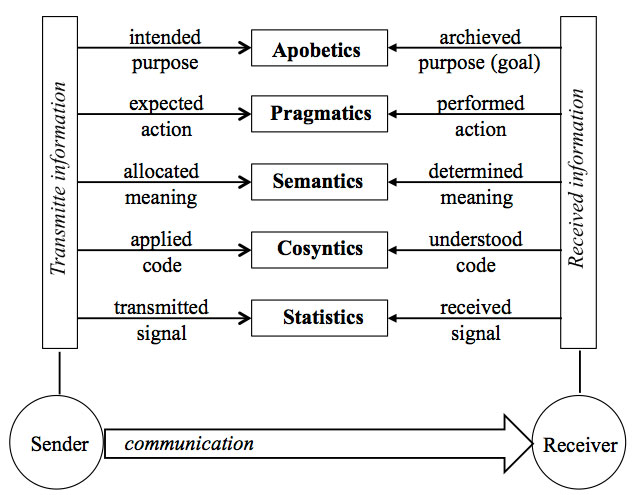
[size=10]Figure 3. A comprehensive diagram of the five levels of Universal Information, according to Gitt.[/size]
A fundamental difference in Gitt’s model is the statement that all levels of information, including the Apobetics (intended purpose) are present in the Sender (figure 3). All other models treat the Sender as merely whatever releases the coded message to a receiver. In Shannon’s case, the Sender is the mindless equipment which initiates transmission to a channel. For Yockey the Sender is DNA, although he considers the ultimate origin of the DNA sequences open. Gitt distinguishes between the original and the intermediate Sender.
Humans interact with coded messages with such phenomenal skill, most don’t even notice what is going on. We discuss verbally with ease. Engineers effortlessly devise various designs: sometimes many copies of machines are built and equipped with message-based processing resources (operating systems, drivers, microchips, etc.). Alternatively, the hardware alone could be distributed and all the processing power provided centrally (such as the ‘dumb terminals’ used before personal computers). To illustrate, intellectual tools such as reading, grammar, and language can be taught to many students in advance. Later it is only necessary to distribute text to the multiple human processors.
The strategy of distributing autonomous processing copies is common in nature. Seeds and bacterial colonies already contain preloaded messages, ribosomes already possess engineered processing parts, and so on.
The word information is used in many ways, which complicates the discussion as to its origin. The analysis shows two families of approaches. One is derived from Shannon’s work and the other is Gitt’s. To a large extent the former addresses the how question: how to measure and quantify information. The latter deals more with the why issue: why is information there, what is it good for?
The algorithmic definition of information, developed by Solomonoff and Kolmogorov, with contributions from Chaitin, is rarely used in the debate about origins and in general discussions about information currently. For this reason it was not discussed in this part of the series.
1) http://creation.com/cis-1
Most of the experts debating the origin of information rely on the mathematical model of communication developed by the late Claude Shannon with its quantitative merits.2–4 Shannon’s fame began with publication of his master’s thesis, which was called “possibly the most important, and also the most famous, master’s thesis of the century”.5
Messages are strings of symbols, like ‘10011101’, ‘ACCTGGTCAA’, and ‘go away’. All messages are composed of symbols taken from a coding alphabet. The English alphabet uses 26 symbols, the DNA code, four, and binary codes use two symbols.
Hubert Yockey is a pioneer in applying Shannon’s theory to biology. Once it was realized that the genetic code uses four nucleobases, abbreviated A, C, G, and T, in combinations of three to code for amino acids, the relevance of Information Theory became quickly apparent. Yockey used the mathematical formalism of Shannon’s work to evaluate the information of cytochrome c proteins, selected due to the large number of sequence examples available. Many proteins are several times larger, or show far less tolerance to variability, as is the case of another example Yockey discusses:
“The pea histone H3 and the chicken histone H3 differ at only three sites, showing almost no change in evolution since the common ancestor. Therefore histones have 122 invariant sites … the information content of an invariant site is 4.139 bits, so the information content of the histones is approximately 4.139 × 122, or 505 bits required just for the invariant sites to determine the histone molecule.”
Yockey seems to believe the information was front-loaded on to DNA about four billion years ago in some primitive organism. This viewpoint is not elaborated on by him and is deduced primarily by his comments that Shannon’s Channel Capacity Theorem ensures transmission of the original message correctly.
Bio-physicist Lee Spetner, Ph.D. from MIT, is a leading information theoretician who wrote the book Not by Chance.27 He is a very lucid participant in Internet debates on evolution and information theory, and is adamant that evolutionary processes quantitatively won’t increase information. In his book, he wrote,
“I don’t say it’s impossible for a mutation to add a little information. It’s just highly improbable on theoretical grounds. But in all the reading I’ve done in the life-sciences literature, I’ve never found a mutation that added information. The NDT says not only that such mutations must occur, they must also be probable enough for a long sequence of them to lead to macroevolution.”
Within Shannon’s framework, it is correct that a random mutation could increase information content. However, one must not automatically conflate ‘more information content’ with good or useful. Although Spetner says information could be in principle created or increased, Dr Werner Gitt, retired Director and Professor at the German Federal Institute of Physics and Technology, denies this:
“Theorem 23: There is no known natural law through which matter can give rise to information, neither is any physical process or material phenomenon known that can do this.”
In his latest book, Gitt refines and explains his conclusions from a lifetime of research on information and its inseparable reliance on an intelligent source. There are various manifestations of information: for example, the spider’s web; the diffraction pattern of butterfly wings; development of embryos; and an organ-playing robot. He introduces the term ‘Universal Information’ to minimize confusion with other usages of the word information:
“Universal Information (UI) is a symbolically encoded, abstractly represented message conveying the expected actions(s) and the intended purposes(s). In this context, ‘message’ is meant to include instructions for carrying out a specific task or eliciting a specific response [emphasis added].”35
Information must be encoded on a series of symbols which satisfy three Necessary Conditions (NC). These are conclusions, based on observation.
NC1: A set of abstract symbols is required.
NC2: The sequence of abstract symbols must be irregular.
NC3: The symbols must be presented in a recognizable form, such as rows, columns, circles, spirals and so on.
Gitt also concludes that UI is embedded in a five-level hierarchy with each level building upon the lower one:
[1]statistics (signal, number of symbols)
[2]cosyntics (set of symbols, grammar)
[3]semantics (meaning)
[4]pragmatics (action)
[5]apobetics (purpose, result).
Gitt believes information is guided by immutable Scientific Laws of Information (SLIs).36,37 Unless shown to be wrong, they deny a naturalist origin for information, and they are:
SLI-1: Information is a non-material entity.
SLI-2: A material entity cannot create a non-material entity.
SLI-3: UI cannot be created by purely random processes.
SLI-4: UI can only be created by an intelligent sender.
SLI-4a: A code system requires an intelligent sender.
SLI-4b: No new UI without an intelligent sender.
SLI-4c: All senders that create UI have a non-material component.
SLI-4d: Every UI transmission chain can be traced back to an original intelligent sender
SLI-4e: Allocating meanings to, and determining meanings from, sequences of symbols are intellectual processes.
SLI-5: The pragmatic attribute of UI requires a machine.
SLI-5a: UI and creative power are required for the design and construction of all machines.
SLI-5b: A functioning machine means that UI is affecting the material domain.
SLI-5c: Machines operate exclusively within the physical– chemical laws of matter.
SLI-5d: Machines cause matter to function in specific ways.
SLI-6: Existing UI is never increased over time by purely physical, chemical processes.
These laws are inconsistent with the assumption stated by Nobel Prize winner and origin-of-life specialist Manfred Eigen: “The logic of life has its origin in physics and chemistry.” The issue of information, the basis of genetics and morphology, has simply been ignored. On the other hand,
Norbert Wiener, a leading pioneer in information theory, understood clearly that, “Information is information, neither matter nor energy. Any materialism that disregards this will not live to see another day.”
It is apparent that Gitt views Shannon’s model as inadequate to handle most aspects of information, and that he means something entirely different by the word ‘information’.
Arch-atheist Richard Dawkins reveals a Shannon orientation to what information means when he wrote, “Information, in the technical sense, is surprise value, measured as the inverse of expected probability.” He adds, “It is a theory which has long held a fascination for me, and I have used it in several of my research papers over the years.” And more specifically,
“The technical definition of ‘information’ was introduced by the American engineer Claude Shannon in 1948. An employee of the Bell Telephone Company, Shannon was concerned to measure information as an economic commodity.”
“DNA carries information in a very computer-like way, and we can measure the genome’s capacity in bits too, if we wish. DNA doesn’t use a binary code, but a quaternary one. Whereas the unit of information in the computer is a 1 or a 0, the unit in DNA can be T, A, C or G. If I tell you that a particular location in a DNA sequence is a T, how much information is conveyed from me to you? Begin by measuring the prior uncertainty. How many possibilities are open before the message ‘T’ arrives? Four. How many possibilities remain after it has arrived? One. So you might think the information transferred is four bits, but actually it is two.”
In articles and discussions among non-specialists, questions are raised such as “Where does the information come from to create wings?” There is an intuition among most of us that adding biological novelty requires information, and more features implies more information. I suspect this is what lies behind claims that evolutionary processes cannot create information, meaning complex new biological features. Even Dawkins subscribes to this intuitive notion of information:
“Imagine writing a book describing the lobster. Now write another book describing the millipede down to the same level of detail. Divide the word-count in one book by the word-count in the other, and you have an approximate estimate of the relative information content of lobster and millipede.”
Stephen C. Meyer, director of the Discovery Institute’s Center for Science and Culture and active member of the Intelligent Design movement, relies on Shannon’s theory for his critiques on naturalism. He recognizes that some sequences of characters serve a deliberate and useful purpose. Meyer says the messages with this property exhibit specified complexity, or specified information.Shannon’s Theory of Communication itself has no need to address the question of usefulness, value, or meaning of transmitted messages. In fact, he later avoided the word information. His concern was how to transmit messages error-free. But Meyer points out that
“… molecular biologists beginning with Francis Crick have equated biological information not only with improbability (or complexity), but also with ‘specificity’, where ‘specificity’ or ‘specified’ has meant ‘necessary to function’.”
I believe Meyer’s definition of information corresponds to Durston’s Functional Information.
[size=10]Figure 1. Shannon’s schematic diagram of a general communication system.2[/size]
William Dembski, another prominent figure in the Intelligent Design movement, is a major leader in the analysis of the properties and calculations of information, and will be referred to in the next parts to this series. He has not reported any analysis of his own on protein or gene sequences, but also accepts that H0–Hf is the relevant measure from Shannon’s work to quantify information.
In part 2 of this series I’ll show that many things are implied in Shannon’s theory that indicate an underlying active intelligence.
Thomas Schneider is a Research Biologist at the National Institutes of Health. His Ph.D. thesis in 1984 was on applying Shannon’s Information Theory to DNA and RNA binding sites and he has continued this work ever since and published extensively.
[size=10]Figure 2. The transmission of genetic message from the DNA tape to the protein tape, according to Yockey.17[/size]
Senders and receivers in information theories
There is common agreement that a sender initiates transmission of a coded message which is received and decoded by a receiver. Figure 1 shows how Shannon depicted this and figure 2 shows Yockey’s version.
[size=10]Figure 3. A comprehensive diagram of the five levels of Universal Information, according to Gitt.[/size]
A fundamental difference in Gitt’s model is the statement that all levels of information, including the Apobetics (intended purpose) are present in the Sender (figure 3). All other models treat the Sender as merely whatever releases the coded message to a receiver. In Shannon’s case, the Sender is the mindless equipment which initiates transmission to a channel. For Yockey the Sender is DNA, although he considers the ultimate origin of the DNA sequences open. Gitt distinguishes between the original and the intermediate Sender.
Humans intuitively develop coded information systems
Humans interact with coded messages with such phenomenal skill, most don’t even notice what is going on. We discuss verbally with ease. Engineers effortlessly devise various designs: sometimes many copies of machines are built and equipped with message-based processing resources (operating systems, drivers, microchips, etc.). Alternatively, the hardware alone could be distributed and all the processing power provided centrally (such as the ‘dumb terminals’ used before personal computers). To illustrate, intellectual tools such as reading, grammar, and language can be taught to many students in advance. Later it is only necessary to distribute text to the multiple human processors.
The strategy of distributing autonomous processing copies is common in nature. Seeds and bacterial colonies already contain preloaded messages, ribosomes already possess engineered processing parts, and so on.
Conclusion
The word information is used in many ways, which complicates the discussion as to its origin. The analysis shows two families of approaches. One is derived from Shannon’s work and the other is Gitt’s. To a large extent the former addresses the how question: how to measure and quantify information. The latter deals more with the why issue: why is information there, what is it good for?
The algorithmic definition of information, developed by Solomonoff and Kolmogorov, with contributions from Chaitin, is rarely used in the debate about origins and in general discussions about information currently. For this reason it was not discussed in this part of the series.
1) http://creation.com/cis-1

